| Audience | Data engineers, analytics engineers, and technical marketers |
| Prerequisites | An Identity Resolution project |
Understand how Identity Resolution groups records, applies matching rules, and maintains identity stability over time.
Overview
Identity Resolution groups input records that refer to the same real-world entity into resolved identities. It does this by building and maintaining an identity graph based on the identifiers and rules you configure.
Each resolved identity is represented by a synthetic ht_id.
- During incremental runs,
ht_idvalues remain stable unless new data causes two existing identities to merge. - When identities merge, one
ht_idsurvives and the others collapse into it. - Full re-runs rebuild the graph from scratch and do not guarantee
ht_idstability.
This page explains how Identity Resolution behaves conceptually, independent of any specific UI or setup steps.
Explore the interactive architecture diagram →
See how data flows and where Identity Resolution fits in your stack.
Identity graphs
An identity graph connects records through shared identifiers.
- Input records act as nodes
- Identifiers create edges between records
- Connected groups of records form resolved identities
If two records share a matching identifier (for example, the same email), they are connected in the graph. If no valid connection exists, they remain part of separate identities.
How records connect—and which connections are allowed—is entirely determined by your configured identifiers and rules.
Deterministic matching
By default, Identity Resolution uses deterministic matching, which relies on exact identifier equality.
With deterministic matching:
- Identifier values must match exactly to connect records
- Matching behavior is predictable and explainable
- Re-running the graph with the same data and rules produces the same groupings (excluding full re-runs or rule changes)
Deterministic matching provides a stable foundation for analytics, activation, and operational workflows where correctness and auditability matter.
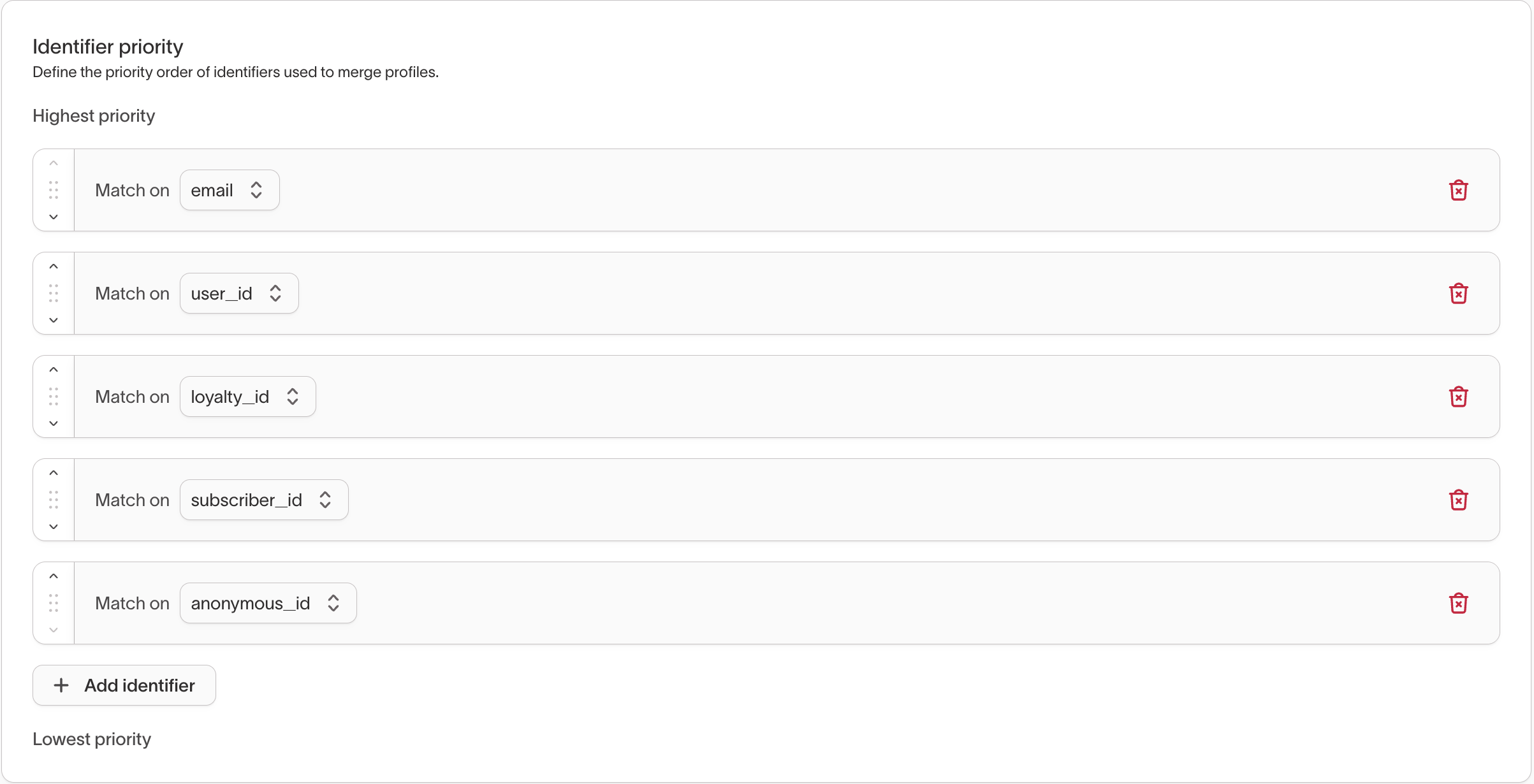
Identifiers and merge priority
Identifiers define how records are allowed to connect in the identity graph.
For each identifier, you configure:
- Which column contains the identifier value
- The priority order relative to other identifiers
- Optional limits on how many distinct values an identity can contain
When a record contains multiple identifiers, Identity Resolution evaluates them in priority order.
Higher-priority identifiers are applied first and can prevent lower-priority identifiers from creating unintended merges. This ordering controls how aggressively records are linked as new data arrives.
Identifier limits and over-merge protection
Identifier limits prevent identities from growing too large due to shared, reused, or low-quality identifiers.
A limit defines a rule such as:
“An identity may contain at most N distinct values of this identifier type.”
When a merge would violate a limit, Identity Resolution uses both priority and limits to determine the outcome:
-
Higher-priority identifier exceeds its limit
- The merge is blocked, and the record remains part of a separate identity.
-
Lower-priority identifier exceeds its limit
- The identity retains only the first N values.
- Additional values are ignored for matching purposes.
This behavior prevents unrelated records from collapsing into a single identity while still allowing high-confidence identifiers to drive resolution.

Incremental runs and identity stability
Identity Resolution processes data incrementally as new or updated records arrive. Each input model's timestamp column determines which rows are net new and need to be processed.
During incremental runs:
- Existing identities typically retain their
ht_id - New records attach to existing identities when matches are found
- New identities are created when no valid matches exist
- Previously separate identities may merge if new data connects them
When a merge happens, the lower-numbered ht_id absorbs the higher-numbered one. For example, if new data links ht10 and ht14, the two identities collapse into ht10 and ht14 is dropped. The dropped ht_id is no longer present in the next run's output, but all of its records appear on the surviving identity. This is expected behavior — it reflects that Identity Resolution has learned the two profiles refer to the same entity.
Full re-runs
A full re-run recomputes the graph from an empty state. This happens when:
- You make an identifier limit rule stricter — for example, lowering the threshold on an existing limit, or adding a new limit rule
- A large amount of bad data requires resetting the graph. Smaller corrections can usually be handled with the profile reprocessing API instead, which avoids a full re-run
After a full re-run:
ht_idvalues are not guaranteed to match previous runs- A given
ht_idvalue from yesterday's graph may be assigned to a completely different real-world entity today
The practical implication
For day-to-day incremental runs, ht_id values are stable. The one common change is when new or updated data shows that two previously distinct identities are actually the same — one ht_id survives, the other is dropped, and its records show up on the surviving identity. This is expected and intentional.
A full re-run is different: it reassigns ht_id values from scratch. If a downstream system stores ht_id as a primary key, you'd need to re-sync every record after a full re-run to keep that system consistent with the warehouse. For activation guidance, see Sync and activation guidance.
From resolved identities to profiles
Identity Resolution produces resolved identities represented by ht_id. How those identities are exposed downstream depends on how you consume the outputs.
Common patterns include:
-
Golden Record
- A flattened, one-row-per-identity table
- Uses survivorship rules (recency, frequency, source priority, arrays) to select canonical values
- Often used for analytics, activation, and Customer 360 use cases
-
Customer Studio
- Uses Golden Record as the parent model
- Allows non-technical users to define traits, audiences, and journeys
A resolved identity exists independently of Golden Record. Golden Record and Customer Studio define how identities are represented and consumed, not how they are resolved.