
Amazon Athena is an interactive query service that makes it easy to analyze data in Amazon S3 using standard SQL. Athena is serverless, so there is no infrastructure to manage, and you pay only for the queries that you run.
Overview
Hightouch lets you pull data stored in Amazon Athena and push it to downstream destinations. Connecting Hightouch to Amazon Athena requires some setup in both platforms. In Amazon, you need to make sure the AWS credentials you will use to connect Hightouch has the correct permissions.
You may need to allowlist Hightouch's IP addresses to let our systems connect to your warehouse. Reference our networking docs to determine which IP addresses you need to allowlist.
Required permissions
The AWS user that you use to connect to Athena must have the following permissions:
Read and list permissions for Athena resources and execute permissions for Athena queries:
ListWorkGroupsListDataCatalogsListDatabasesListTableMetadataStartQueryExecutionGetQueryExecutionGetQueryResultsGetQueryResultsStream
Read and write permissions for the output location in S3 to both write the results to S3, read them back, and perform cleanup:
PutObjectListBucketListBucketMultipartUploadsListMultipartUploadPartsGetBucketLocationGetObjectAbortMultipartUploadDeleteObject
See the AWS managed policy AmazonAthenaFullAccess
for reference.
If you are using Lake Formation for managing permissions you need to grant database permissions to the AWS user that you use to connect to Athena, otherwise no databases load when configuring the source.
Connection configuration
To get started, go to the Sources overview page and click the Add source button. Select Amazon Athena and follow the steps below.
Configure your credentials
You can either select AWS credentials you've previously configured in Hightouch or choose to add New credentials directly from this page.
The credentials must be for a user who has permission to access Athena and the S3 output location. Refer to the required permissions section for permission details and to the AWS credential configuration docs for credential setup information.
Configure your Amazon Athena source
Enter the following fields into Hightouch:
- Athena workgroup you previously set up in AWS.
- (Optional) Query output location—you only need to enter this if your workgroup doesn't have an output location configured. This is an S3 path.
- Data catalog name
- Database name
- (Advanced) VPC connection endpoint-if you wish to connect to Athena through a private VPC endpoint, please contact Hightouch and we can provide the endpoint necessary for this step.
Workgroup and data catalog options populate depending on your AWS credentials. If you don't see the expected values, confirm your AWS credentials and click Refresh. Your database options populate depending on your selected data catalog.
Choose your sync engine
For optimal performance, Hightouch tracks incremental changes in your data model—such as added, changed, or removed rows—and only syncs those records. You can choose between two different sync engines for this work.
The Basic engine requires read-only access to Amazon Athena. Hightouch executes a query in your database, reads all query results, and then determines incremental changes using Hightouch's infrastructure. This engine is easier to set up since it requires read—not write—access to Amazon Athena.
The Lightning engine requires read and write access to Amazon Athena. The engine stores previously synced data in a separate schema in Amazon Athena managed by Hightouch. In other words, the engine uses Amazon Athena to track incremental changes to your data rather than performing these calculations in Hightouch. Therefore, these computations are completed more quickly.
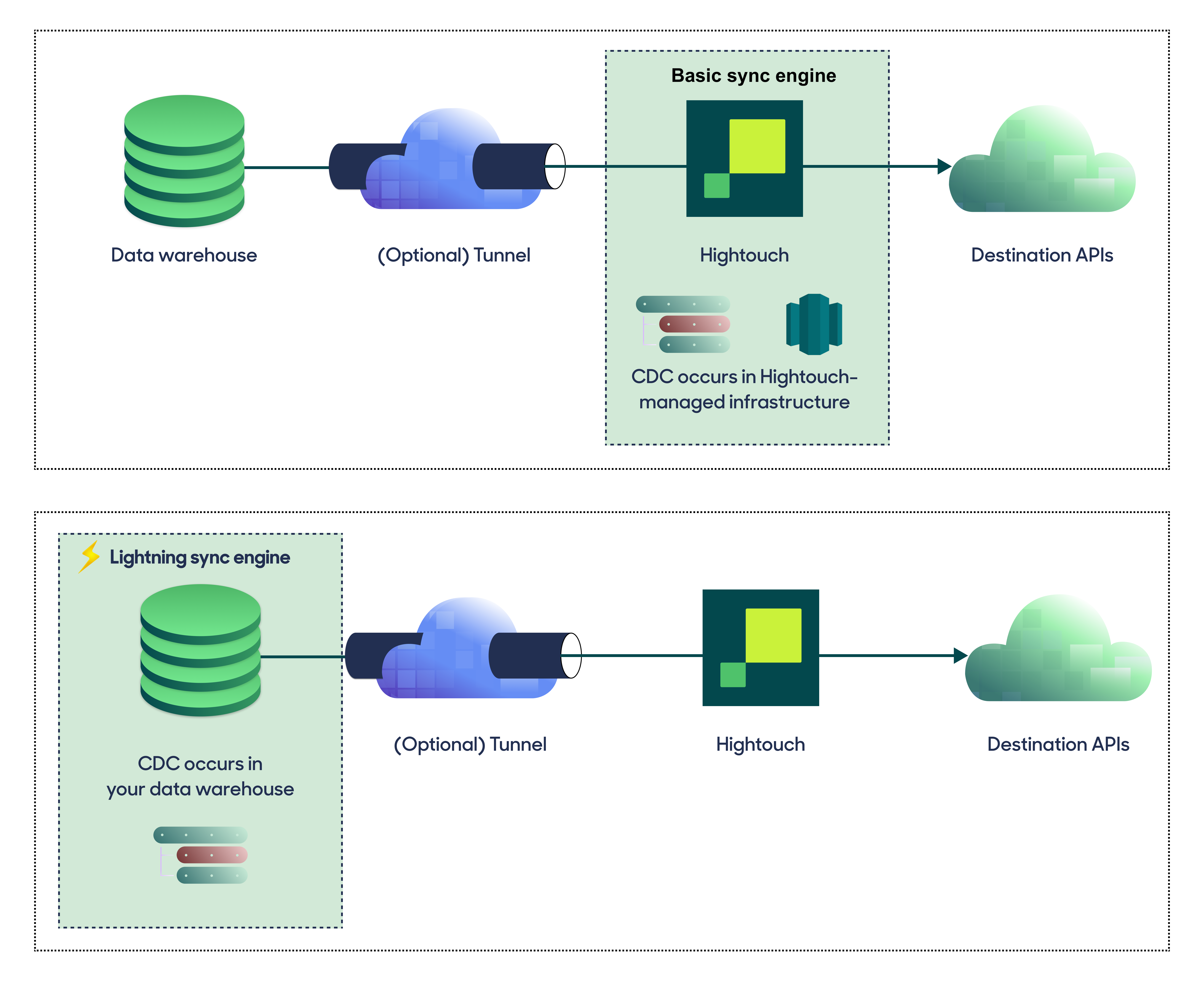
If you select the Basic engine, you cannot switch to the Lightning engine later. Once you've configured the Lightning engine, you can't move back to the Basic engine without recreating Amazon Athena as a source.
To learn more, check out the Lightning sync engine docs.
Basic versus Lightning engine comparison
| Criteria | Basic sync engine | Lightning sync engine |
|---|---|---|
| Performance | Slower | Quicker |
| Ideal for large data models (over 100 thousand rows) | No | Yes |
| Reliability | Normal | High |
| Resilience to sync interruptions | Normal | High |
| Extra features | None | Warehouse Sync Logs, Match Booster, Identity Resolution |
| Ease of setup | Simpler | More involved |
| Location of change data capture | Hightouch infrastructure | Amazon Athena schemas managed by Hightouch |
| Required permissions in Amazon Athena | Read-only | Read and write |
| Ability to switch | You can't move to the Lightning engine once Basic is configured | You can't move to the Basic engine once Lightning is configured |
Lightning engine setup
Hightouch uses two schemas (hightouch_planner and hightouch_audit) for storing logs of previously synced data. Hightouch must be able to read and write to these schemas, but the specific schema names might vary.
-- Required for the Lightning engine
CREATE SCHEMA IF NOT EXISTS <catalog>.hightouch_planner;
-- For sync logs, optional
CREATE SCHEMA IF NOT EXISTS <catalog>.hightouch_audit;
Test your connection
When setting up a source for the first time, Hightouch validates the following:
- Network connectivity
- Amazon Athena credentials
- Permission to list schemas and tables
- Permission to write to
hightouch_plannerschema - Permission to write to
hightouch_auditschema
All configurations must pass the first three, while those with the Lightning engine must pass all of them.
Some sources may initially fail connection tests due to timeouts. Once a connection is established, subsequent API requests should happen more quickly, so it's best to retry tests if they first fail. You can do this by clicking Test again.
If you've retried the tests and verified your credentials are correct but the tests are still failing, don't hesitate to .
Next steps
Once your source configuration has passed the necessary validation, your source setup is complete. Next, you can set up models to define which data you want to pull from Athena.
The Athena source supports these modeling methods:
- writing a query in the SQL editor
- using the visual table selector
- leveraging existing dbt models
- leveraging existing Looker Looks
Data types
Hightouch parses most Athena data types into JavaScript types before sending them to your destination. Hightouch leaves the following Athena data types as strings:
BIGINTARRAYMAP
Read more about Athena data types in the Athena documentation.
Tips and troubleshooting
Performance considerations
The following Service Quota changes to Amazon Athena are recommended in order to support fast and reliable syncs:
- Active DML queries: 400
- To support concurrent
CREATE TABLE ASqueries which are DML statements.
- To support concurrent