| Audience | Data or analytics engineers, platform admins, technical marketers |
| Prerequisites |
|
This page covers how to create and configure schema models in Customer Studio. If you haven't decided on your grain, model topology, or naming conventions yet, start with Plan your data model.
What you'll learn
After reading this article, you'll know how to:
- Create parent, related, and event models
- Configure columns — visibility, aliases, privacy, semantics, and suggestions
- Define relationships — types, merge columns, and through relationships
- Label your models so the audience builder uses intuitive language
- Validate your schema before building production audiences
- Troubleshoot common schema issues like type mismatches and broken relationships
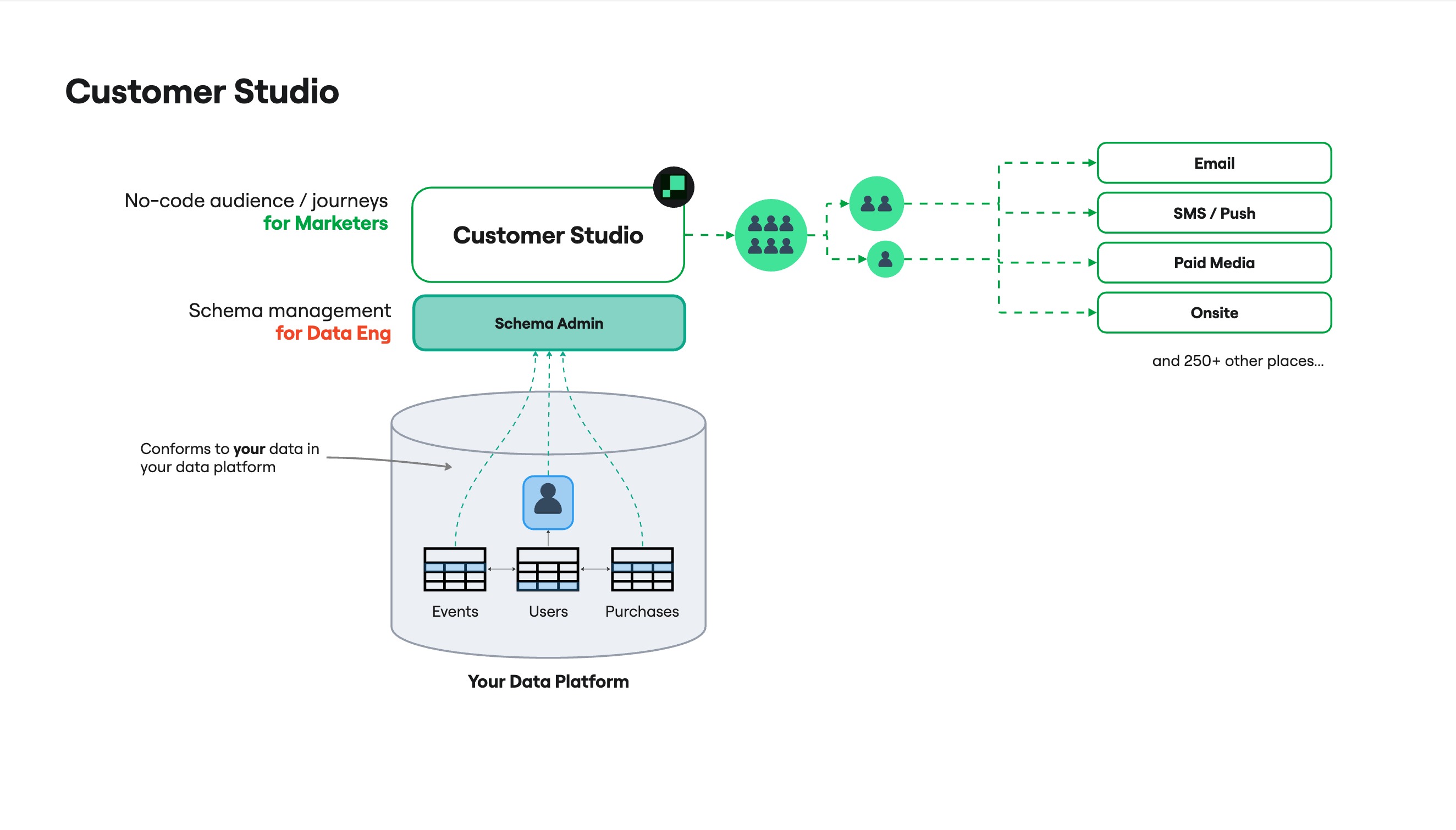
Overview
Before marketers can build audiences visually, data teams configure the schema in Customer Studio. The schema defines which models, relationships, and events are available in the audience builder.
In Customer Studio, you'll create:
- Parent model: The base entity audiences are built from (for example,
Users) - Related models: Additional context joined to the parent (for example,
Households) - Event models: Timestamped behaviors (for example,
Product Viewed)
Once configured, marketers can build audiences using warehouse data. You can also add general models to make additional warehouse tables available for agent queries without including them in the audience schema. If marketers need a reusable calculated value that isn't available as a column — like lifetime value or days since last purchase — create a trait.
Create models
Define the parent model
The parent model is the core dataset for audience building — most commonly a Users table, but it could also be Accounts, Households, or Devices.
Before choosing a table, decide what one row should represent. This is your targeting grain — see Plan your data model for guidance.
Requirements:
- One row per entity (for example, one row per user)
- A stable, unique primary key (for example,
user_id) - Fields useful for filtering (for example,
email,region,created_at)
Before adding a model, run SELECT * FROM your_table LIMIT 1 in your
warehouse. If returning a single row is slow, the model likely depends on
expensive joins. Flatten or materialize it upstream before adding it to your
schema to improve audience preview and sync performance. See Build a
presentation layer
first.
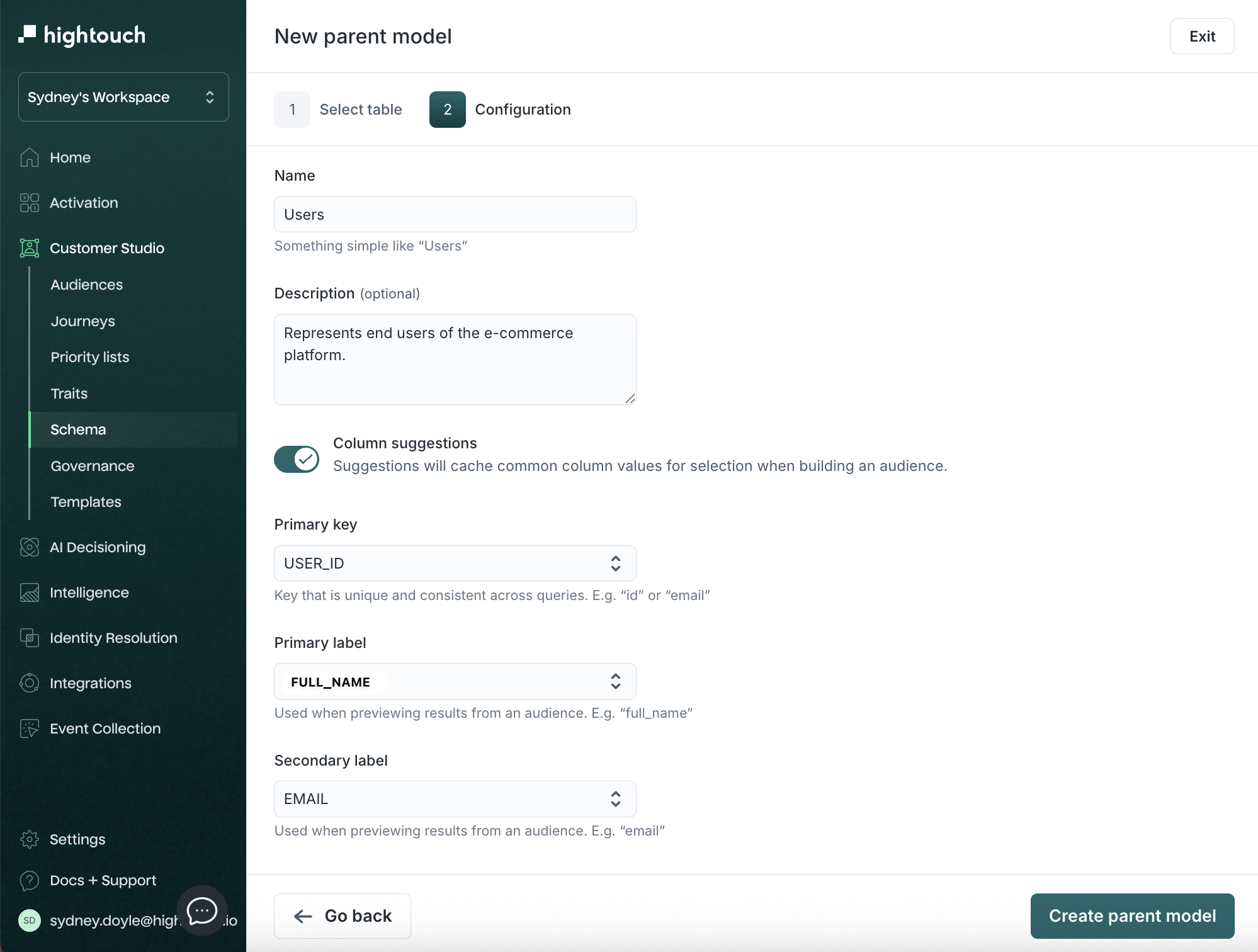
Create a parent model
-
Go to Customer Studio → Schema.
-
Click Create parent model.
-
Select a modeling method:
- Table selector (default)
- SQL query
- dbt model
- dbt Cloud model
- Looker model
- Sigma model
-
Preview the results, then click Continue.
-
Configure the model:
| Field | Description | Example |
|---|---|---|
| Name | Display name in Customer Studio | Users |
| Description | Context for your team | Represents end users of the platform |
| Primary key | Unique ID column | user_id |
| Primary label | Display name in audience previews | full_name or email |
| Secondary label | Additional preview context | signup_date |
Column suggestions may be available depending on your workspace configuration. When enabled, they help marketers discover useful filter values in the audience builder.
-
Click Create parent model.
Add related models
Related models join to the parent via a foreign key and provide additional filtering context—like purchases, subscriptions, or devices.
Examples:
- Households linked to People by
household_id - Subscriptions linked to Companies by
company_id
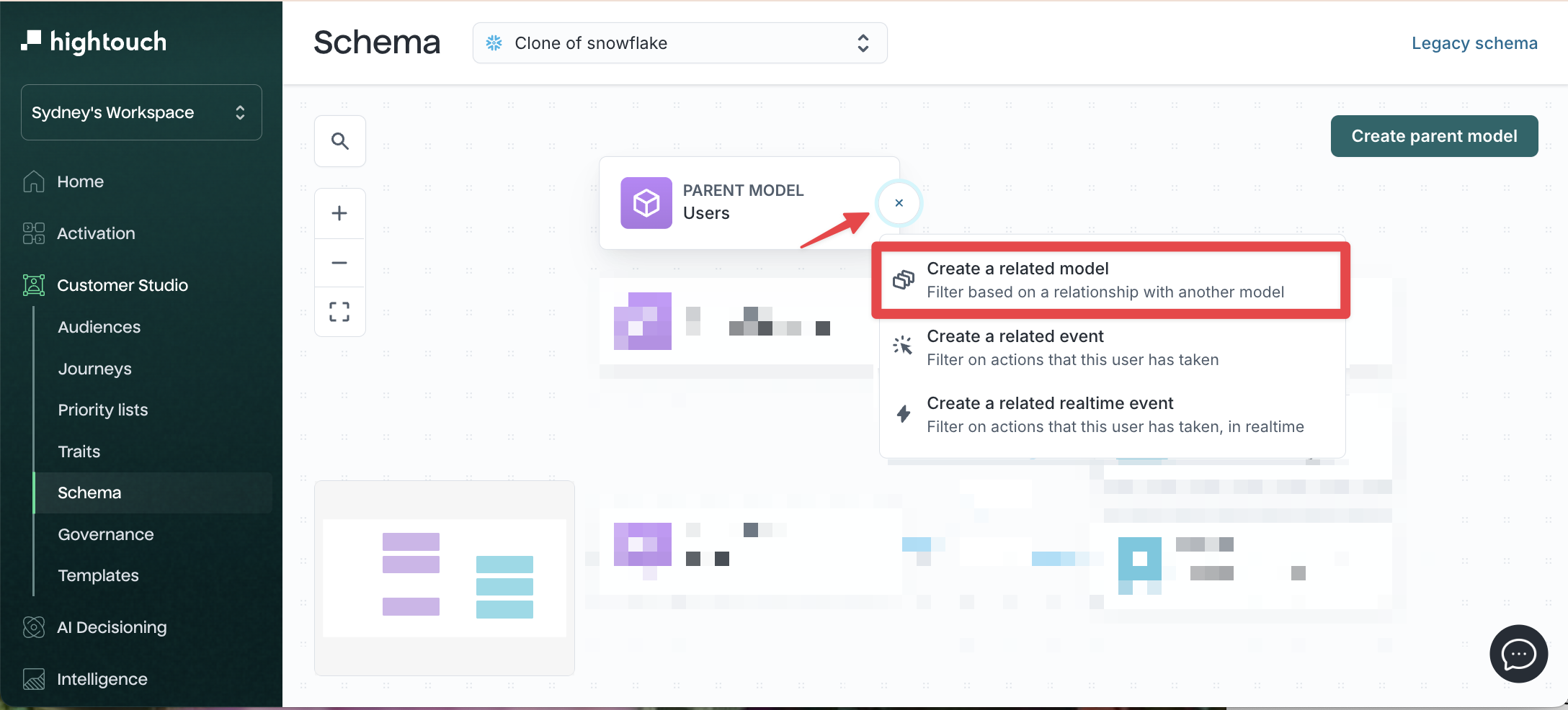
Create a related model
-
Go to Customer Studio → Schema.
-
Click the + icon next to your parent model.
-
Select Create related model.
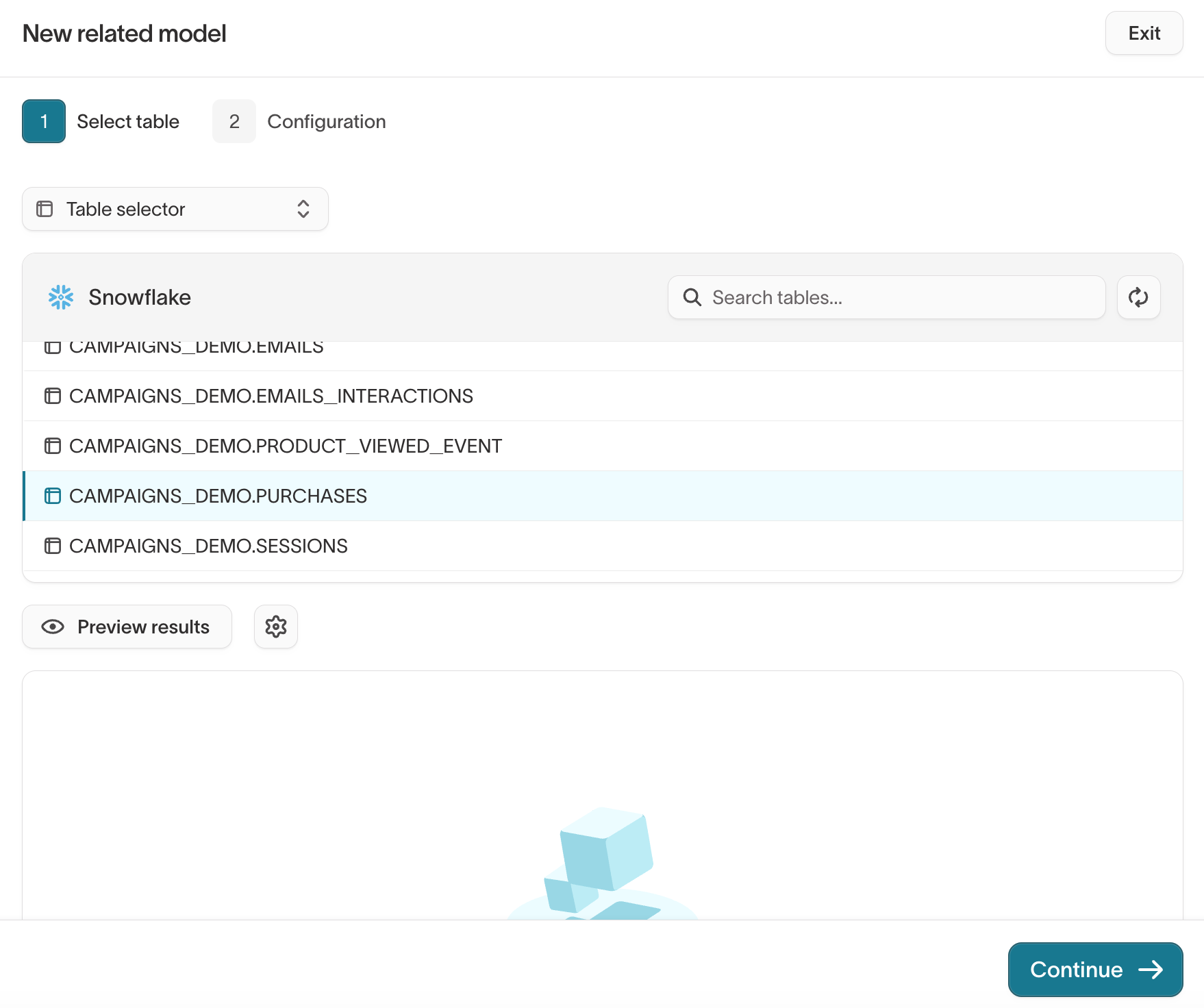
-
Choose your table or modeling method and preview results.
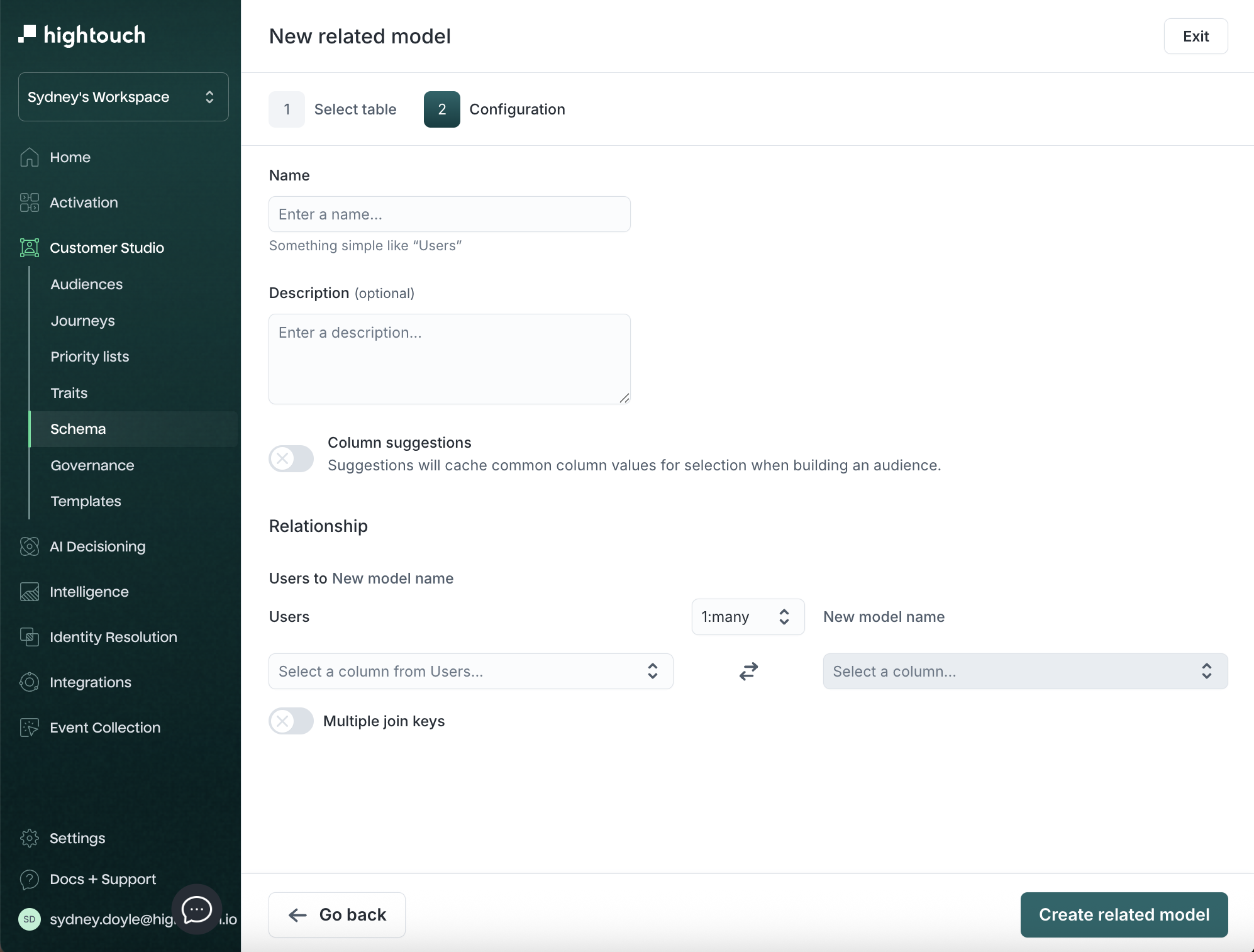
- Configure the relationship:
| Field | Description | Example |
|---|---|---|
| Name | Related model name | Households |
| Description | Context for marketers | User purchase records |
| Relationship | Cardinality (1:many, etc.) | 1:many |
| Foreign key (join key) | Column joining models | user_id |
To match on multiple columns (for example, product_id and location_id), enable multiple join keys in the relationship configuration.
The primary key uniquely identifies rows. The join key connects tables.
-
(Optional) If you want to add columns from the parent model onto the related model, turn on Merge columns.
-
Click Create related model.
Add event models
Event models represent timestamped behaviors like page views, logins, or checkouts. These power both real-time and historical audience logic.
Requirements:
- At least one timestamp column (for example,
created_at) - A foreign key linking to the parent model (for example,
user_id)
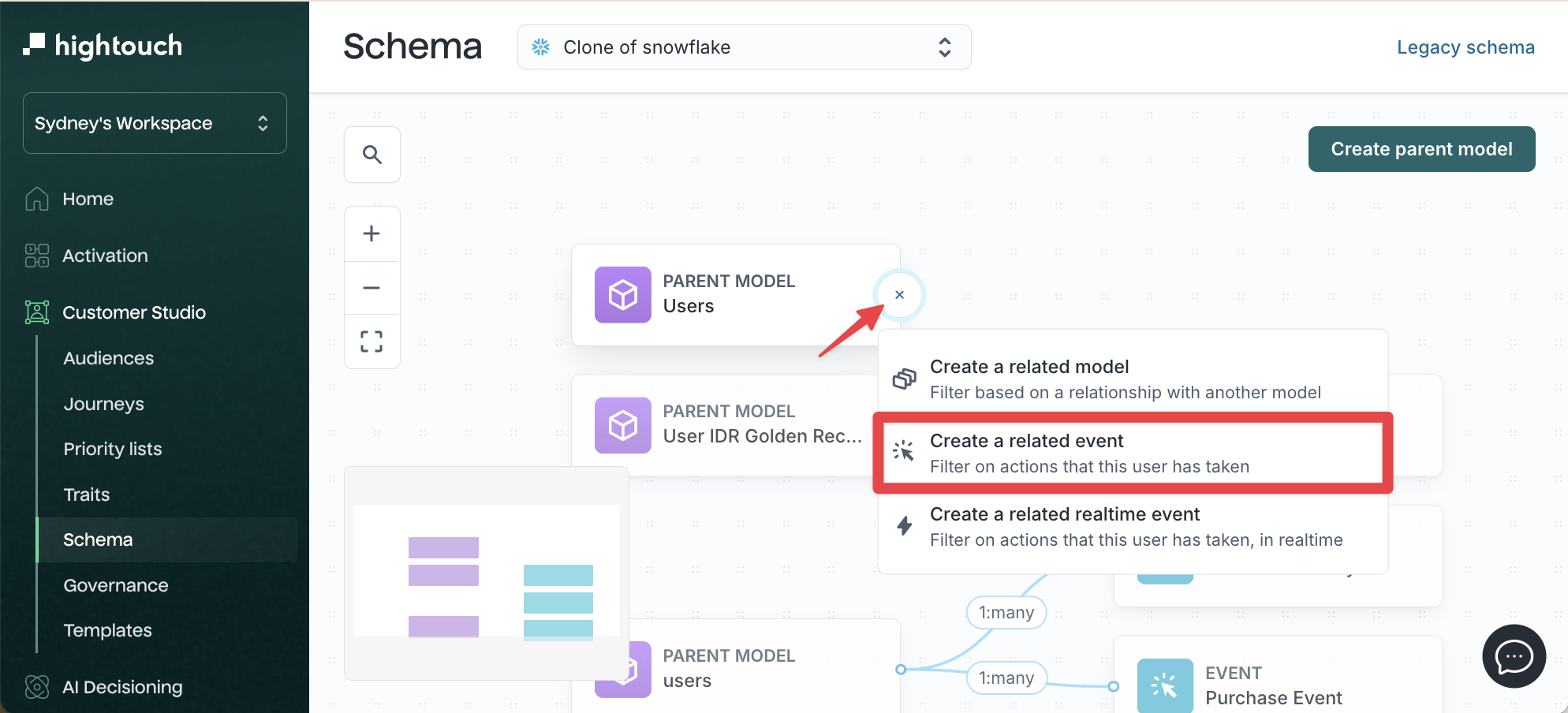
Create an event model
-
Go to Customer Studio → Schema.
-
Click the + icon next to your parent model.
-
Select Create related event.
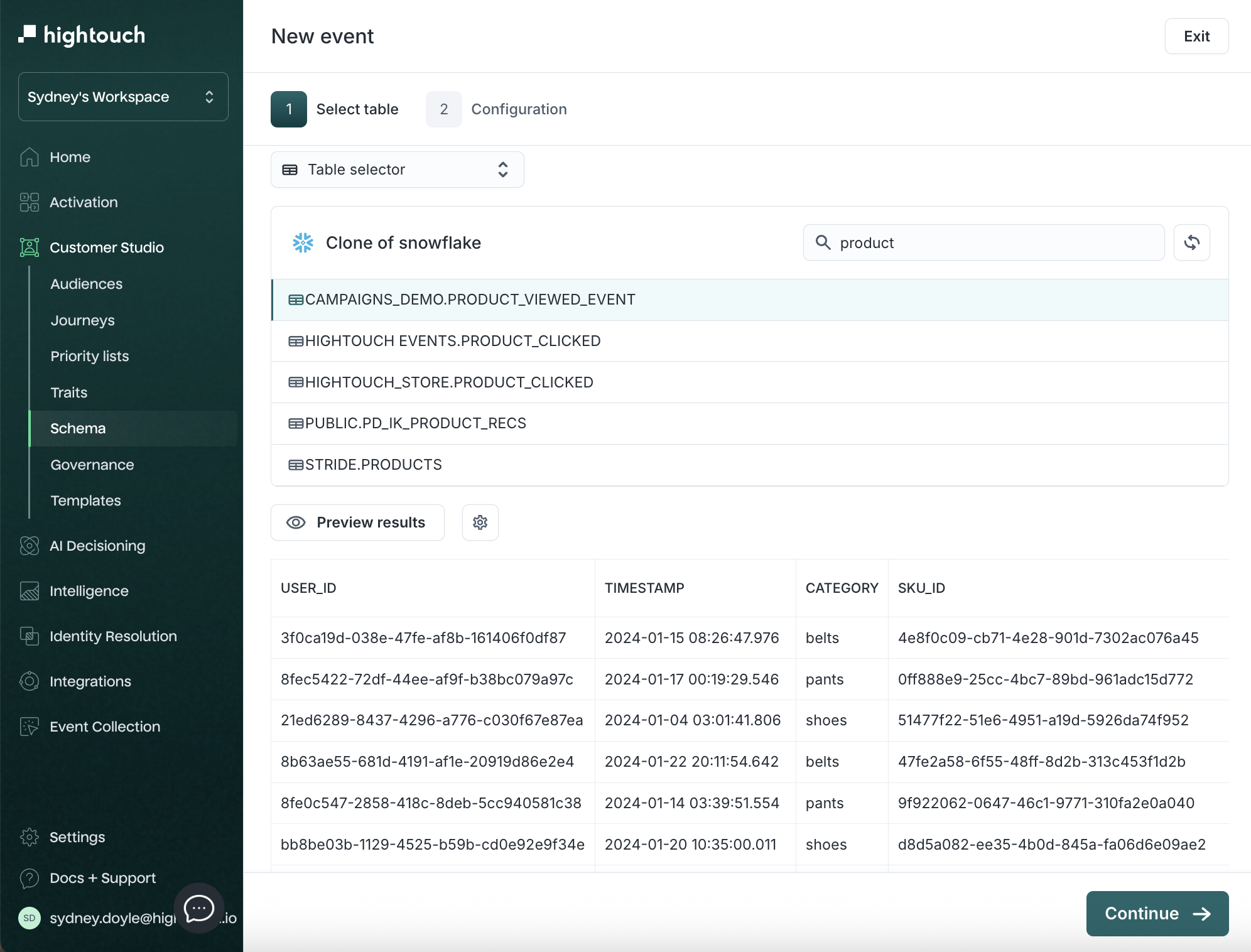
-
Choose your table or modeling method and preview results.
-
Click Continue.
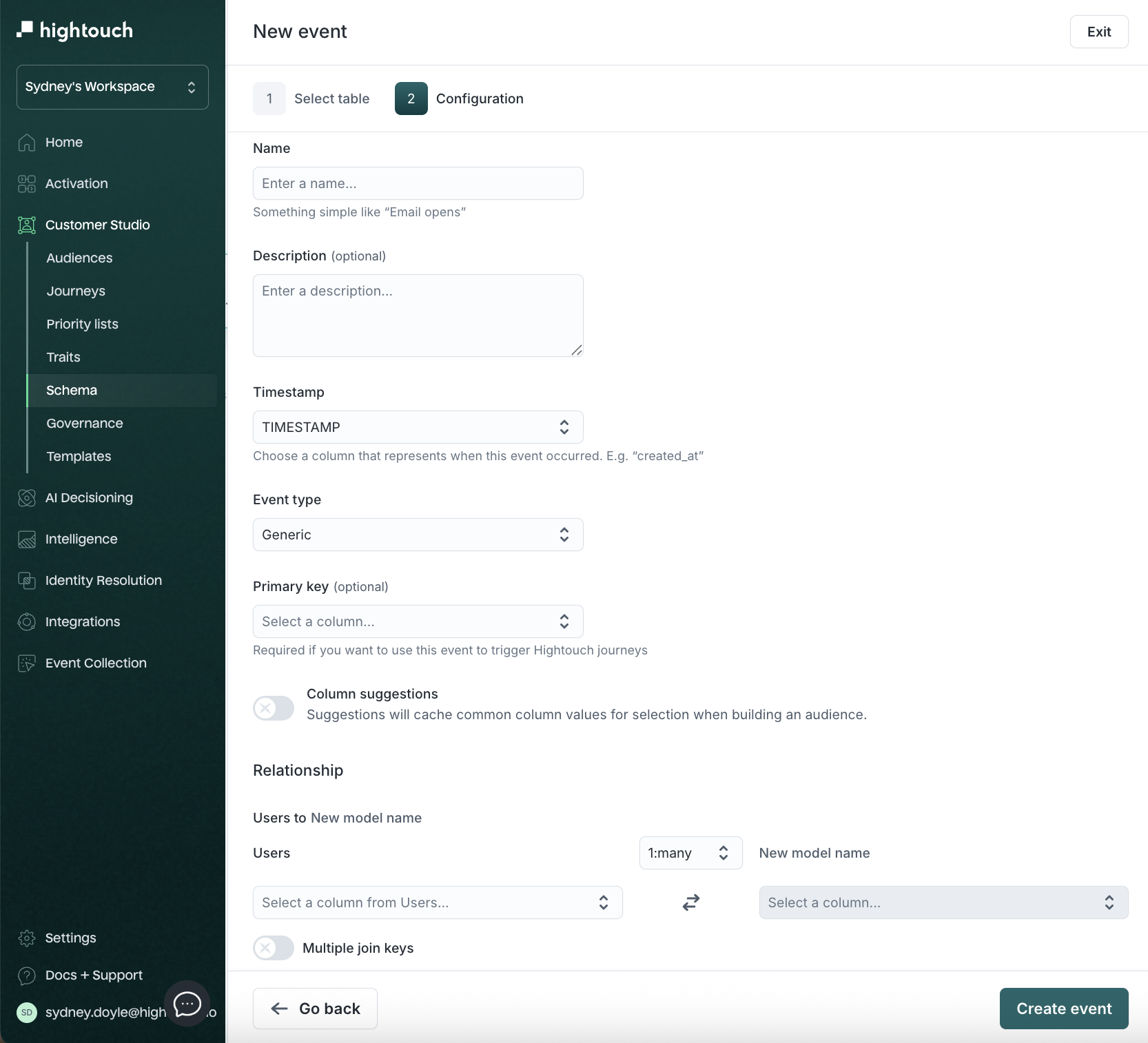
-
Configure the event:
| Field | Description | Example |
|---|---|---|
| Name | Event name | Product Viewed |
| Description | Context for marketers | Tracks user product views |
| Timestamp column | When the event occurred | created_at |
| Event type | Category (Generic, Checkout) | Generic |
| Primary key | For referencing or triggering Journeys | event_id |
| Relationship | Cardinality to parent | 1:many |
| Foreign key (join key) | Column joining event with parent | user_id |
The primary key uniquely identifies a row. The join key links it to another model. Often, the primary key in the parent model becomes the join key in a related model, but they serve distinct purposes.
-
(Optional) If you want to add columns from the parent model onto the event model, turn on Merge columns.
-
Click Create event.
If all events live in a single table, you can create multiple event models by filtering by event type (for example, Page View and Add to Cart).
Name events for marketers
Use a consistent, human-readable naming pattern. In most cases, Object + Verb works well because it groups related actions together in the audience builder:
Product Viewed,Cart Abandoned,Checkout Started,Subscription Renewed
Avoid names that expose implementation details instead of business meaning, like track_event_v2 or page_view_prod. If multiple events come from one event stream, split them into separate event models when marketers will think of them as different behaviors.
Configure columns
Use the Columns tab to control which fields appear in Customer Studio and how marketers interact with them.
- Open the model you want to update.
- Go to the
Columnstab.
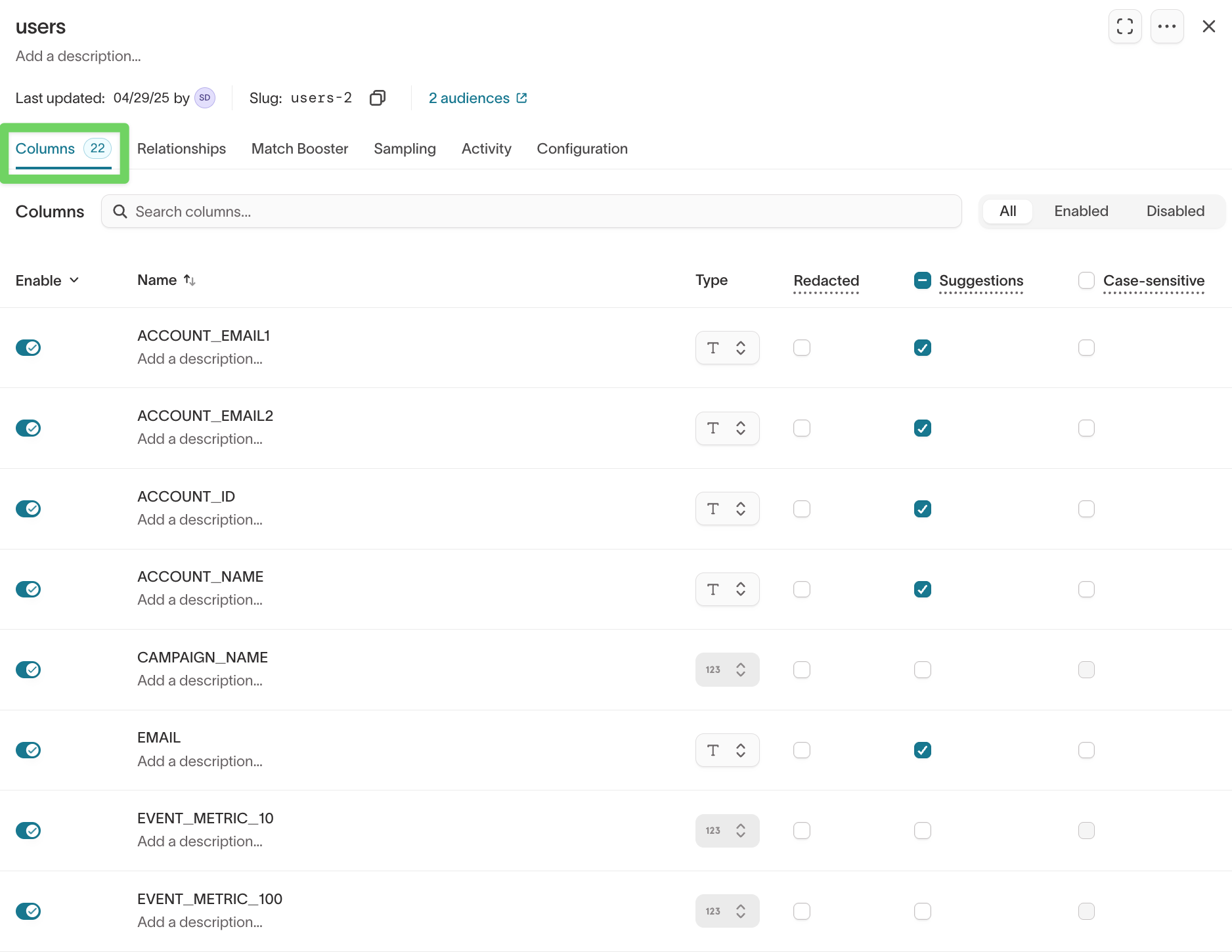
Enable or exclude columns
Use the toggle next to each column to control whether it appears in Customer Studio.
Disable columns when:
- the field isn't useful for filtering (for example, internal IDs)
- the field adds noise for marketers
- you don't want it available in audience filters
If a field is useful only for sync mappings or operational workflows, consider hiding it from the audience builder even if you keep it available elsewhere in the schema configuration.
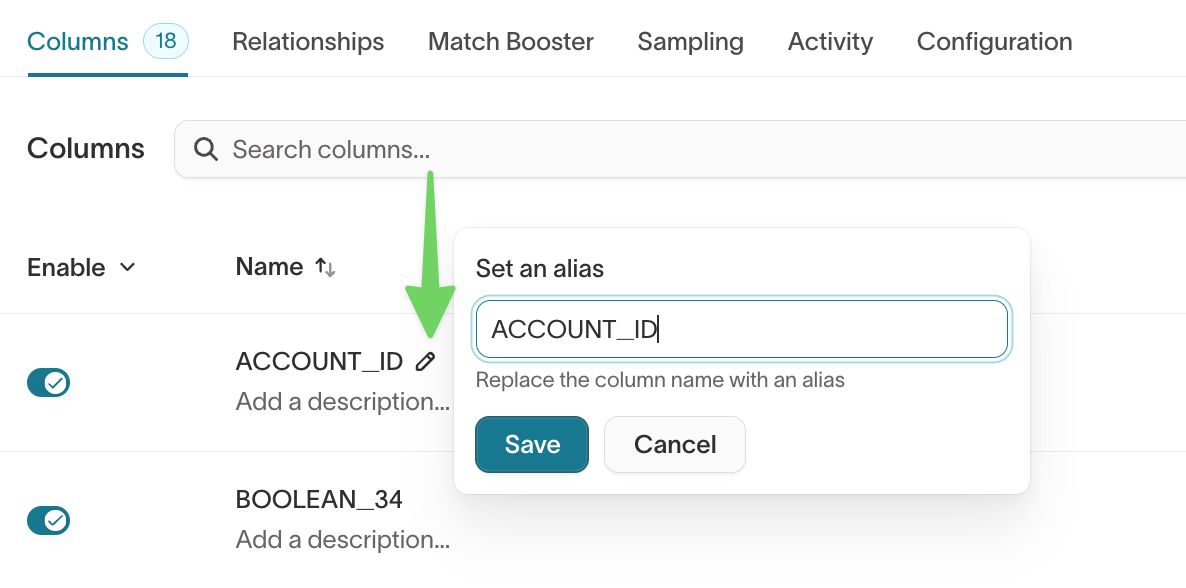
Rename columns using aliases
Aliases control how columns appear in the audience builder.
For example:
geo_region→Regioncreated_at→Signup date
To set an alias, hover over the column and click the pencil icon.
Set privacy levels for columns
Privacy levels control how column values appear in places like audience previews and profile exploration, while keeping the column available for filtering.
Use privacy levels for sensitive fields like:
- email addresses
- phone numbers
- internal identifiers
Each column in the Columns tab has a Privacy dropdown. The default value is Unreviewed. Select the appropriate privacy level for each column based on its sensitivity.
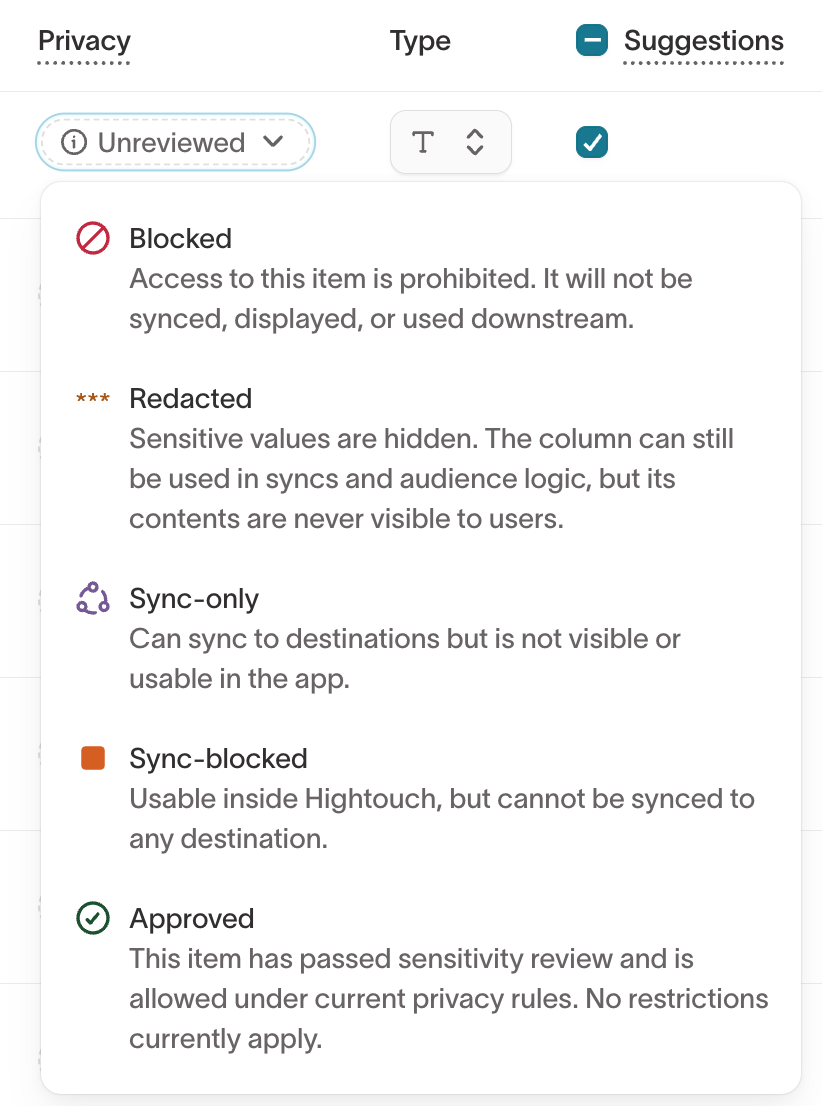
Set privacy levels before marketers begin building audiences. As a starting point:
- Mark email addresses and phone numbers as Redacted if marketers need to filter on them but should not see raw values in previews.
- Mark internal IDs as Sync-only or Sync-blocked when they are operationally useful but not meaningful for audience building.
- Mark fields as Approved only when values are safe to display in previews and profile exploration.
If you're unsure, start more restrictively and loosen visibility later.
Configure case sensitivity
When enabled for your workspace, new string columns added to a schema model default to case-sensitive matching. This means filters like equals and contains in the audience builder distinguish between uppercase and lowercase values (for example, "Nike" and "nike" are treated as different values).
This applies to columns added after case-sensitivity was enabled for your workspace. Existing columns retain their previous behavior unless you update them.
If your audience filters depend on case-insensitive matching, review new
columns and adjust settings as needed. Case sensitivity is configured per
column in the Columns tab.
Add descriptions and metadata
Aliases control how columns appear in the audience builder, but marketers also need to understand what values mean. Where possible, add descriptions in your modeling layer (for example, dbt column descriptions) so Customer Studio inherits business context directly. When that's not practical, use the description field on the model.
For columns that need extra context, document:
- Allowed values for enums and status fields (for example,
active,churned,trial) - Units for numeric fields (for example, whether
amountis in dollars or cents) - Null behavior — whether null means unknown, not applicable, or genuinely missing
- Boolean semantics — whether
trueis a raw data flag or derived logic
Add descriptions to models and columns. Include a definition, an example value, or when helpful, a brief note about how marketers should use the data. Good descriptions reduce questions and make the schema easier to use.
Enable filter value suggestions
Suggestions help marketers choose common values from a dropdown when filtering (for example, brands like Nike or Adidas).
As a rule of thumb, enable suggestions for columns with fewer than 100 distinct values — fields like region, plan_tier, or status. High-cardinality columns (for example, email addresses or order IDs) don't benefit from suggestions and add unnecessary compute during refreshes.
Suggestions are off by default to reduce query overhead. Enable them selectively where preloaded dropdown values help marketers build filters faster. You can control how often suggestions refresh from the model's Configuration settings. For most teams, a weekly refresh is sufficient once the schema is stable — schedule refreshes outside peak analytics hours when possible.
Refresh columns from your source
If you add or remove columns in your warehouse, you can refresh the columns available in the model.
- Open the model.
- Click the three-dot menu.
- Select Refresh columns available in source.

Define relationships
Use the Relationships tab to define how models connect in your schema. These relationships power cross-model filtering in the audience builder.
- Open the model you want to update.
- Go to the
Relationshipstab.
Relationship types
Relationships define how rows connect across models:
| Relationship | Use when... | Example |
|---|---|---|
1:many | One parent maps to many related records | One user has many purchases |
1:1 | One parent maps to one related record | A company has one active subscription |
many:1 | Many records map to one shared record | Many users belong to one household |
Use 1:many for most behavioral data (for example, purchases, page views). Use many:1 when referencing shared entities like plans or organizations.
Validate before saving a relationship
Before saving any relationship, confirm the following:
- Join keys use the same data type on both sides. A type mismatch (for example,
integeron one side andbiginton the other) can cause silent join failures. - The relationship reflects the actual business cardinality, not just whatever setting lets it save. A
1:1relationship on data that's actually1:manyproduces wrong audience counts. - If using multiple join keys, every key pair must match for a row to join. A partial match returns no results.
- After editing or recreating a relationship, re-check any dependent traits, audiences, or journeys that referenced it. Recreating a relationship generates a new internal ID, and existing references keep pointing at the old one until you update them.
Add a relationship
- Click Add relationship.
- Choose the relationship type (for example,
1:manyormany:1). - Select the model you want to connect to.
- Choose join keys for each model.
- Click Save.

Edit an existing relationship
To update a relationship:
- Go to the
Relationshipstab. - Select the relationship you want to edit (for example,
Purchase History). - Update join keys, the connected model, or cardinality.
- Click Save changes.
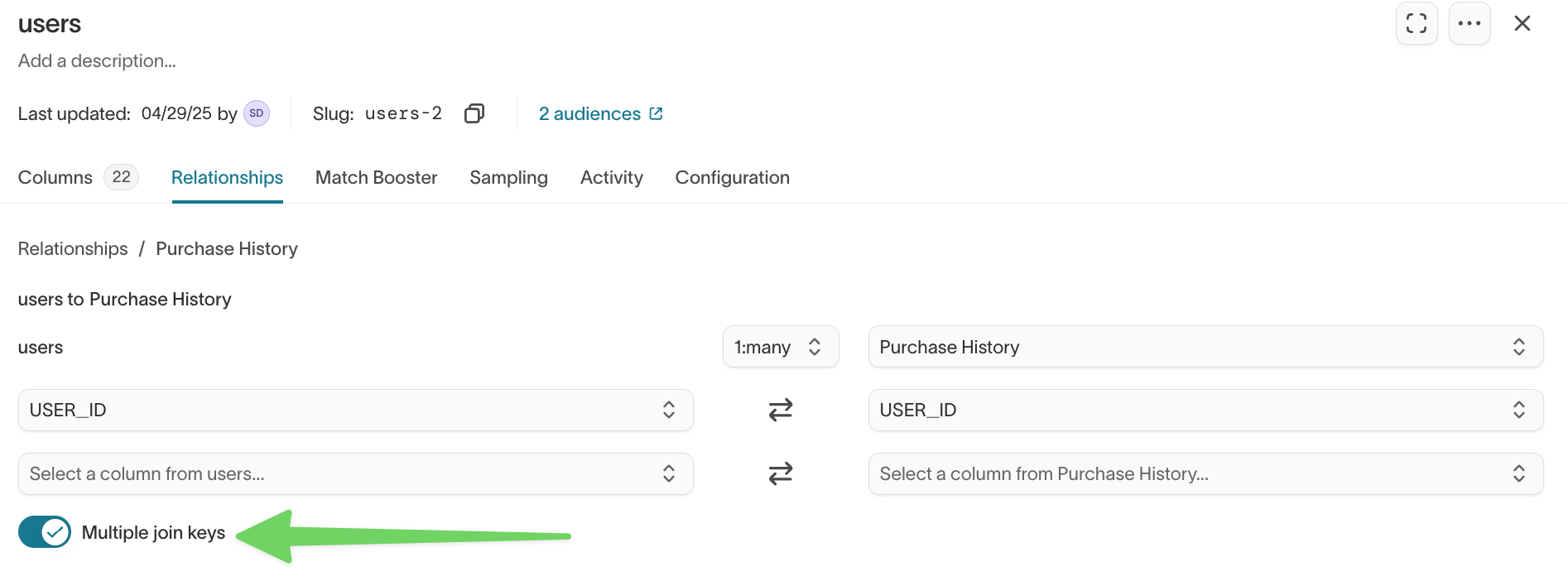
Use multiple join keys
Multiple join keys let you match models on two or more columns. This is helpful when you need compound keys (for example, product_id and location_id).
Enable multiple join keys
- Open the model and go to the
Relationshipstab. - Select the relationship you want to edit.
- Toggle Multiple join keys ON.
- Select the additional join key columns.
- Click Save changes.
Merge columns across models
Merge columns let you surface fields from a parent model into a related or event model, so marketers can filter on those fields without switching models.
This is useful when:
- the related/event model doesn't include marketer-friendly fields like region or plan name
- you want to reduce duplication across traits or audiences
- marketers need both behavior (events) and customer attributes in the same workflow
Merged columns appear as read-only copies in the target model and are filterable like native fields.
Merge column directionality
Merge columns copy fields from one side of a relationship into the other. Whether you can merge depends on the cardinality:
- In a
1:1relationship, you can merge in either direction. - In a
many:1relationship, you can merge columns from the1side into themanyside — for example, merging Household columns into Users when many users belong to one household. - In a
1:manyrelationship, the merge toggle is not available. To merge in this direction, view the relationship from the other model where it appears asmany:1. - The Merge columns toggle appears on the relationship configuration page. If you don't see it, check the cardinality — merge is only available on
1:1andmany:1relationships.
Use merge columns for frequently used context that helps marketers filter more naturally — like adding region or plan_tier onto purchase records. Don't merge everything from adjacent models; keep it to fields marketers actually need in filters.
If a value only exists on a related or event model and you need it in sync field mappings, you have three options: merge it onto the parent, create a trait that rolls it up, or move the value upstream to the parent model directly.
Examples:
- Users → Purchases — Merge
geo_regionfrom Users so marketers can filter Purchases by customer location. - Products → Product Viewed events — Merge
brandorcategoryfrom Products so marketers can build audiences based on product attributes.
Enable merge columns
- Open the model and go to the
Relationshipstab. - Select the relationship you want to edit.
- Under Merge columns, toggle Merge columns ON.
- Choose the columns you want to merge, then click Save changes.
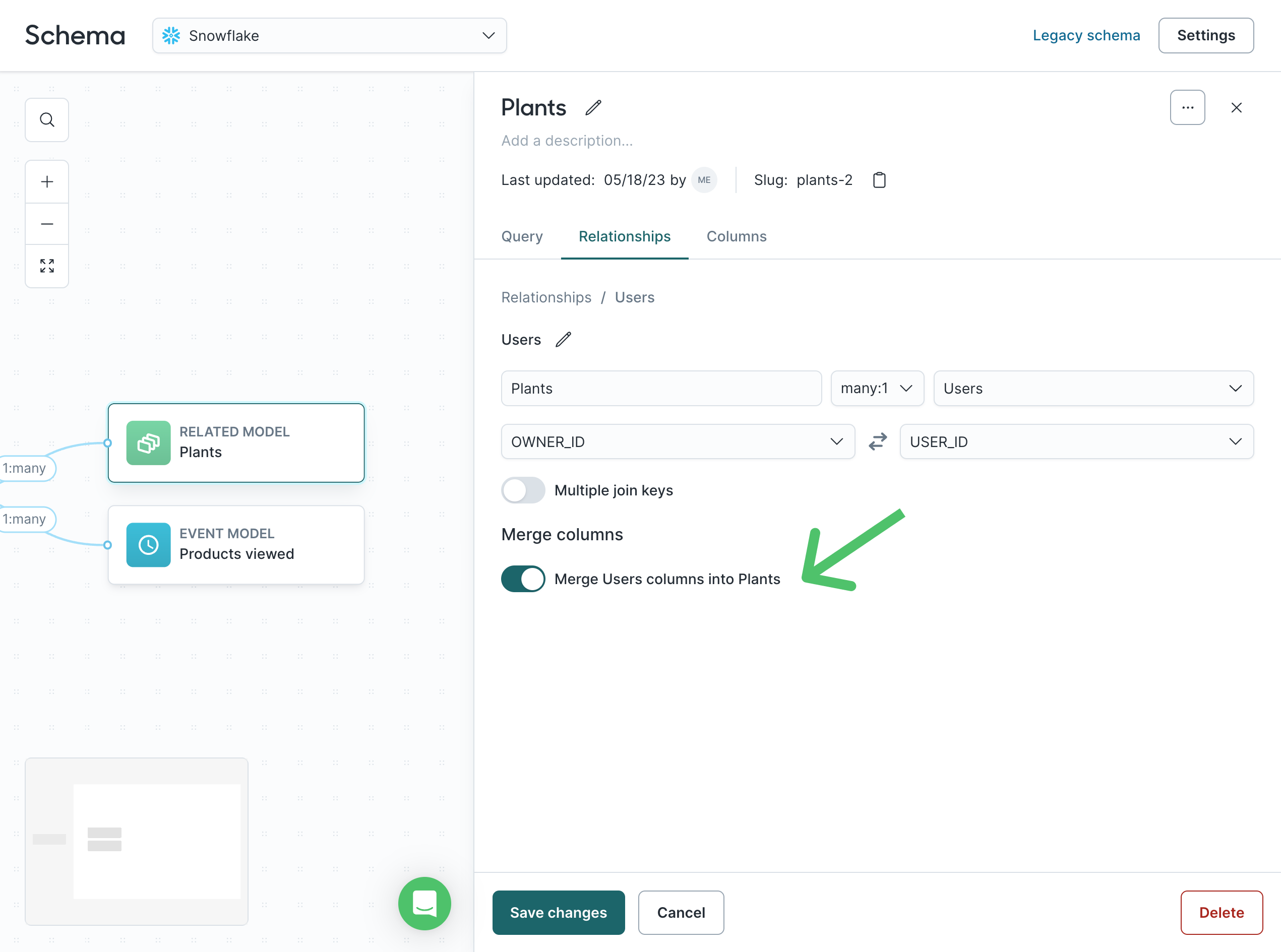
If you don't see the merge columns toggle, check the relationship configuration and cardinality. Merge columns require a relationship where Hightouch can resolve a single value per row.
Through relationships
Use a direct relationship whenever two models can be joined directly. Use a through relationship only when the model you need is reachable only through an intermediate table. Through relationships are more brittle — if any link in the chain is deleted, recreated, or has its join key changed, the entire path can break without a clear error message.
Through relationships let you connect two models through an intermediate model (a linking table). This is useful for many-to-many scenarios.
Example: Users → Memberships → Subscriptions
- Users join to Memberships on
user_id - Memberships join to Subscriptions on
subscription_id
This enables filters like "users with an active subscription" without duplicating logic.

Set up a through relationship
Through relationships are configured in the Relationships tab of your parent model.
-
Create the two direct relationships:
- Users → Memberships (
1:many) - Memberships → Subscriptions (
many:1)

- Users → Memberships (
-
Select your parent model, then open the
Relationshipstab. -
Click Add through relationship.
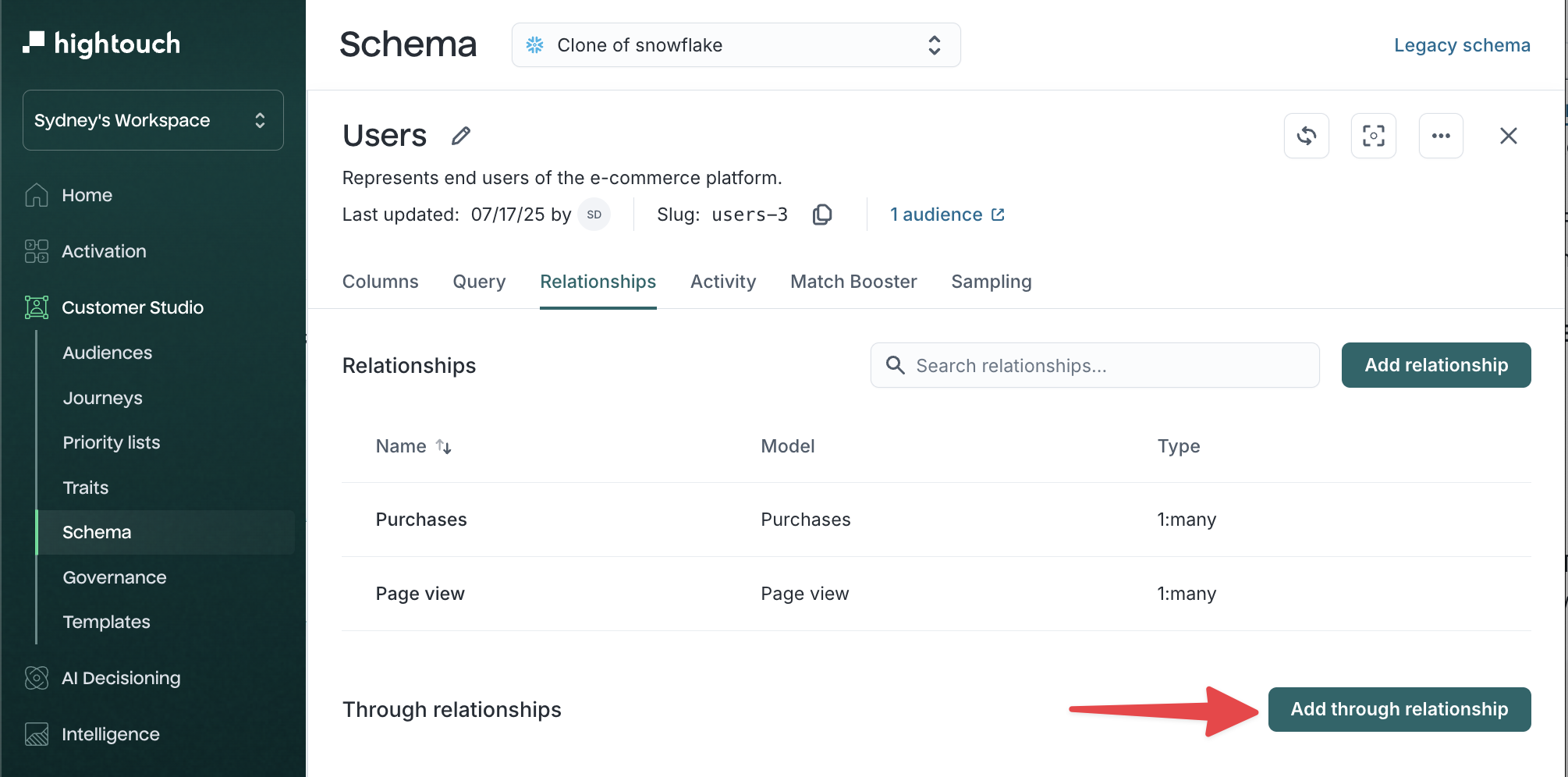
-
Under Access, select the model you want to access (for example,
Products).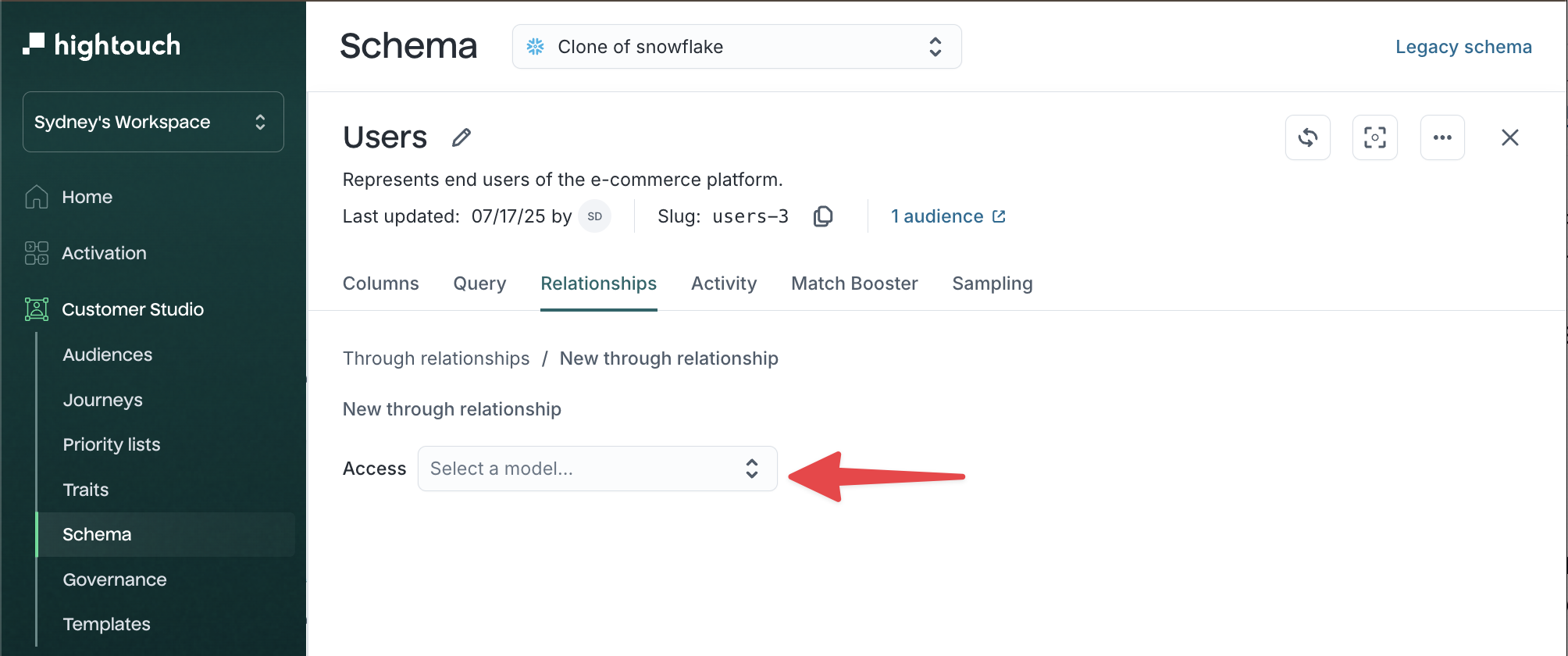
-
In the through dropdown, choose the indirect path that connects your parent model to the target model (for example,
Purchases→Products).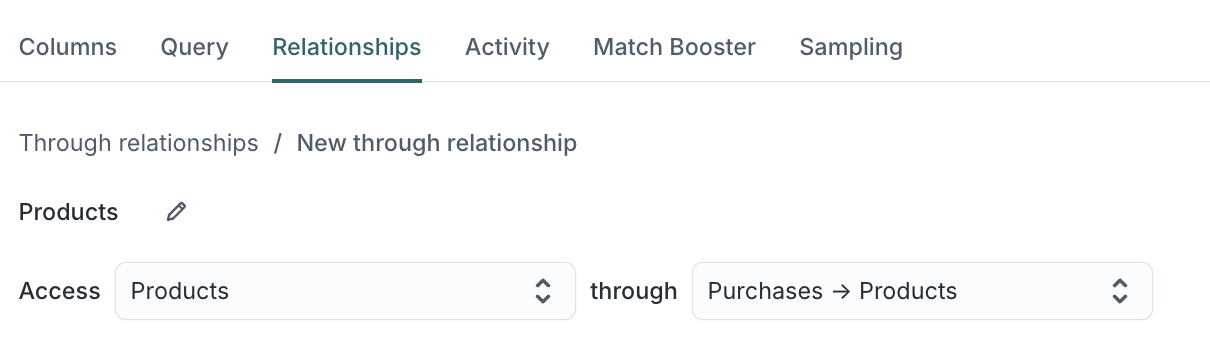
-
Click Save.
Label your models
Schema labels tell Hightouch what business entity each model represents, so the audience builder can use more intuitive language. When labels are applied, filters and insights adjust automatically — for example, a People-labeled parent model with a Household-labeled related model lets marketers build audiences using both individual and household-level data.
Label models based on the business entity they represent, not the warehouse table they came from:
Peoplefor individual users, leads, or contactsHouseholdsfor shared consumer entitiesAccountsfor companies or organizations
If a model could reasonably be interpreted in multiple ways, choose the label that best matches how marketers will use it in audience building. When you label a model as Households or Accounts, you'll also need to select a name column (for example, last name for households, company name for accounts).
Validate your schema
After creating your models and relationships, verify the schema works as expected before building production audiences.
Check primary key uniqueness
Each row in your parent model should have a unique primary key value. Duplicate keys cause audience membership to be evaluated multiple times for the same entity, leading to inflated counts and unexpected sync behavior. Run a quick query in your warehouse to confirm there are no duplicates:
SELECT primary_key_column, COUNT(*)
FROM your_parent_table
GROUP BY primary_key_column
HAVING COUNT(*) > 1
Confirm join key types match
Open each relationship and verify that the join key columns use the same data type on both sides. A type mismatch (for example, integer on the parent and bigint on the related model) can cause silent join failures. See Keep data types consistent for details.
Test with a simple audience
Create a small test audience using one or two filters and check that the results make sense:
- Does the audience count match what you'd expect from a direct warehouse query?
- Can you preview individual members and verify their attributes look correct?
- Do filters on related and event models return the right subset of parent rows?
If counts are off, the issue is usually a grain mismatch or a misconfigured join key. See Troubleshoot schema issues for common causes.
Verify through-relationship chains
If you use through relationships, test each chain end-to-end. A change to any link in the chain (for example, deleting and recreating one of the intermediate relationships) can break the full path without an obvious error.
Troubleshoot schema issues
Audience counts are unexpectedly high or low
Cause: The parent model grain doesn't match what you expect. If the parent model is at the account grain but you expected user-level targeting, every qualifying account counts as one row — regardless of how many users belong to it.
Resolution: Open the parent model and check what one row represents. If the grain is wrong, switch the parent model to a user-level table or restructure the schema. See Choose the right grain for guidance.
Relationship setup fails with a type error
Cause: A mismatch between the primary key type on one model and the foreign key type on another. For example, an integer primary key on the parent and a bigint foreign key on a related model can cause join failures.
Resolution: Cast both columns to the same type upstream in your warehouse, then open the affected model and select Refresh columns available in source from the three-dot menu.
Traits or audiences break after schema changes
Cause: Renaming columns, changing join keys, or modifying relationships can break traits, audiences, or journeys that reference the old configuration. This is especially common after Git Sync updates that change relationship IDs.
Resolution:
- Go to Customer Studio → Schema and check the
Activitytab on the affected model to see what changed. - Open the broken trait or audience and update it to reference the current column or relationship.
- If the issue is a stale relationship ID (common after Git Sync changes), delete and recreate the relationship.
A field exists in the warehouse but doesn't appear in the audience builder
Cause: The column may not be added to the schema, may be disabled, or may be on a related or event model instead of the parent model.
Resolution: Check these in order:
- Open the model, select the three-dot menu, and choose Refresh columns available in source.
- In the
Columnstab, check that the toggle for the column is on. - If the field is on a related or event model, it's available for filtering but won't appear directly in sync field mappings unless exposed as a merge column or trait. See Choose the right model type for guidance on where data should live.
Errors containing "failed to find direct relationship by ID"
Cause: A trait, audience, or journey references a relationship ID that no longer exists. This typically happens when a relationship is deleted and recreated (which generates a new ID), or after a Git Sync update changes relationship IDs.
Resolution:
- Open the affected trait or audience.
- Remove the filter or condition that references the old relationship.
- Re-add it using the current relationship from the schema.
- If the relationship was deleted, recreate it in Customer Studio → Schema first.
Errors containing "bad relationship data"
Cause: This family of errors means the relationship record exists but is inconsistent or incomplete. You may see variants like "bad relationship data, cycle detected," "bad relationship data, no rows returned," or "bad relationship data, no path." Common causes include a partial save that was interrupted, or a relationship that was modified without saving all required fields.
Resolution: Delete the broken relationship and recreate it from scratch. Verify the join key columns exist on both models and use the same data type before saving.
Through-relationship chain breaks after a link changes
Cause: Through relationships depend on a chain of direct relationships. If any link in the chain is deleted, recreated, or has its join key changed, the through relationship can break without a clear error message.
Resolution:
- Open the parent model's
Relationshipstab and check whether the through relationship still shows the correct path. - If the path is broken, delete the through relationship and recreate it after verifying both direct relationships in the chain are intact.
Upstream column changes aren't reflected in Customer Studio
Cause: Customer Studio doesn't automatically detect new or renamed columns in your warehouse.
Resolution:
- Open the affected model in Customer Studio → Schema.
- Select the three-dot menu and choose Refresh columns available in source.
- Update any column aliases if the underlying column name changed.
Manage your schema
Edit a model
To manage models in your schema:
- Go to Customer Studio → Schema.
- Select a model to open its details page.
- Use the tabs across the top to configure the model.
If your team uses Git for version control, you can manage your Customer Studio schema—including parent models, related models, event models, and relationships—using Schema Git Sync. Note that some UI-configured settings are not synced. See Git Sync limitations for Customer Studio schema for details.
Delete a model
- Open the model you want to remove.
- Click the three-dot menu, then select Delete.
Deleting a model removes it from the audience builder. Any audiences using it will break and must be updated.
Enrich match rates
Match Booster enhances match rates by enriching your schema with additional identifiers from Hightouch's identity graph.
- Open your parent model.
- Go to the
Match Boostertab. - Toggle Enable Match Booster.
- Select one or more identifier columns (for example, email or phone).
- Click Initialize Match Booster to start enrichment.
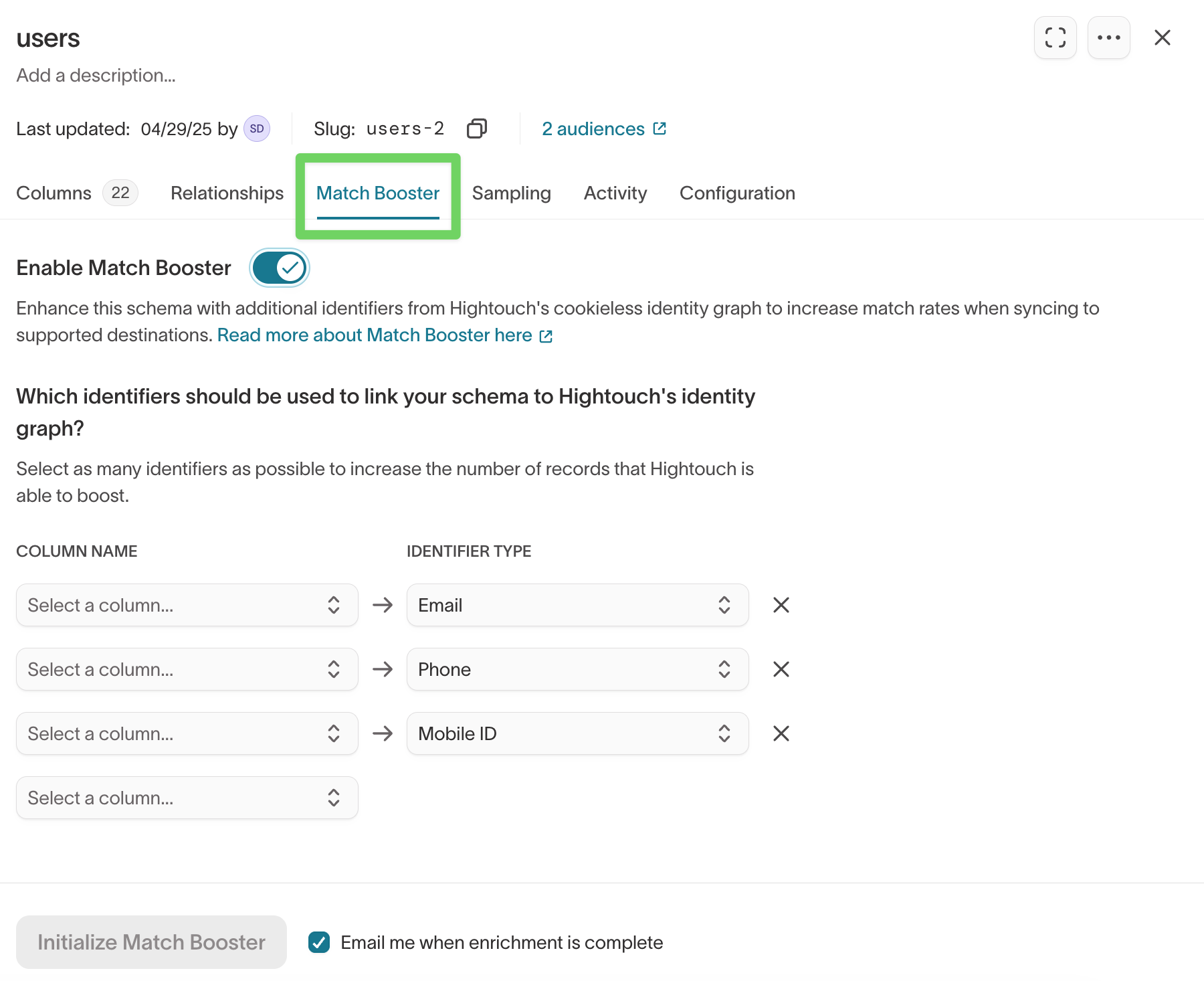
Learn more: Match Booster overview
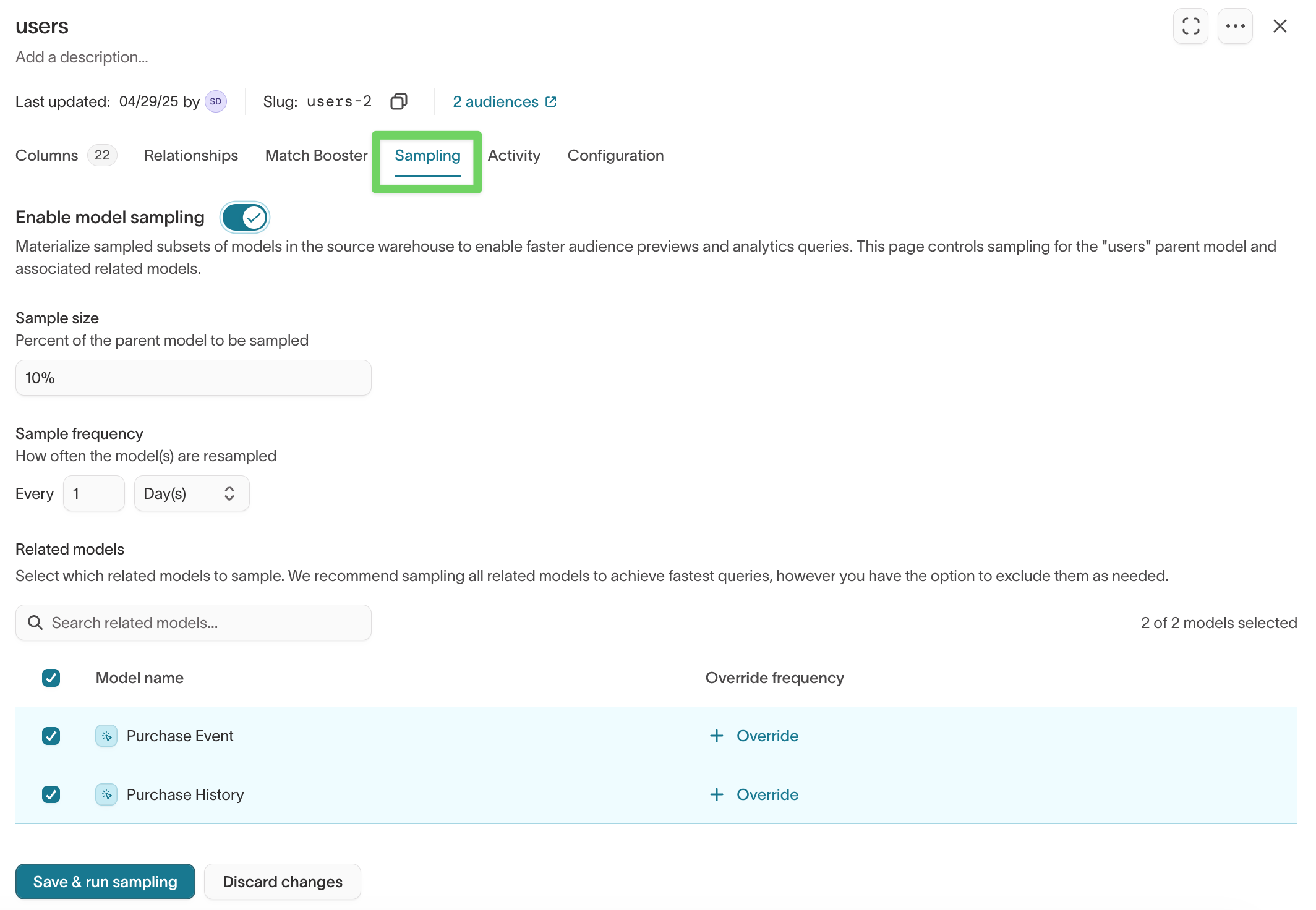
Speed up previews with sampling
Sampling creates a smaller subset of your model data to improve performance when previewing audiences.
- Open your model.
- Go to the
Samplingtab. - Turn on sampling and configure the settings.
- Click Save & run sampling.
Learn more: Sampling
Review model activity
Use the Activity tab to review recent changes and understand how a model is being used.
You can track:
- recent updates to the model definition
- audiences, traits, or syncs that reference the model
- usage history for debugging and cleanup
Update model settings
Use the Configuration tab to manage core model settings such as primary key, preview labels, and column suggestion refresh interval.
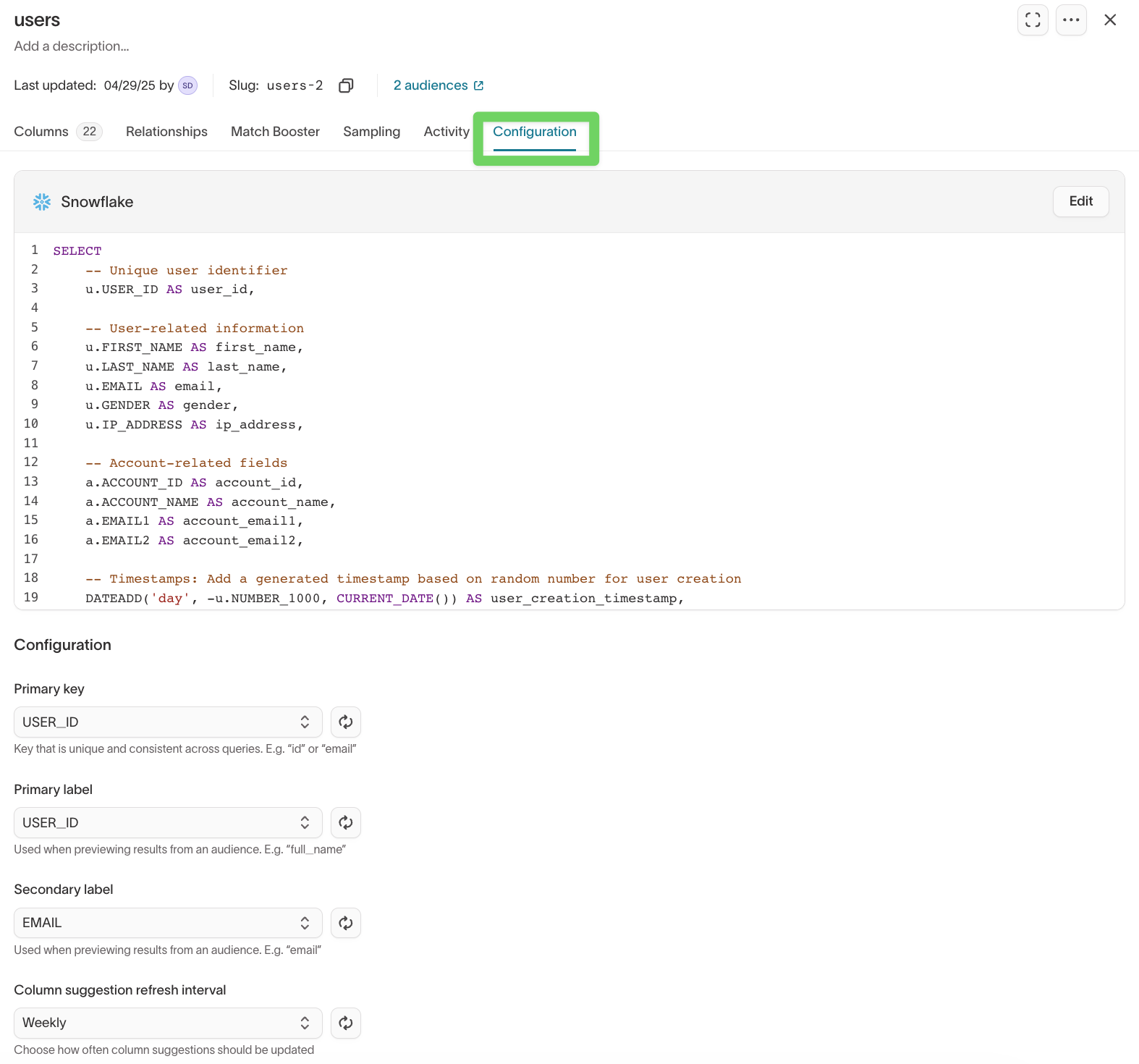
Column suggestion refresh interval
Hightouch can automatically refresh filter suggestions so dropdown values stay up to date as your warehouse data changes.
- Open your model.
- Go to the
Configurationtab. - Under Column suggestion refresh interval, choose how often suggestions should update.
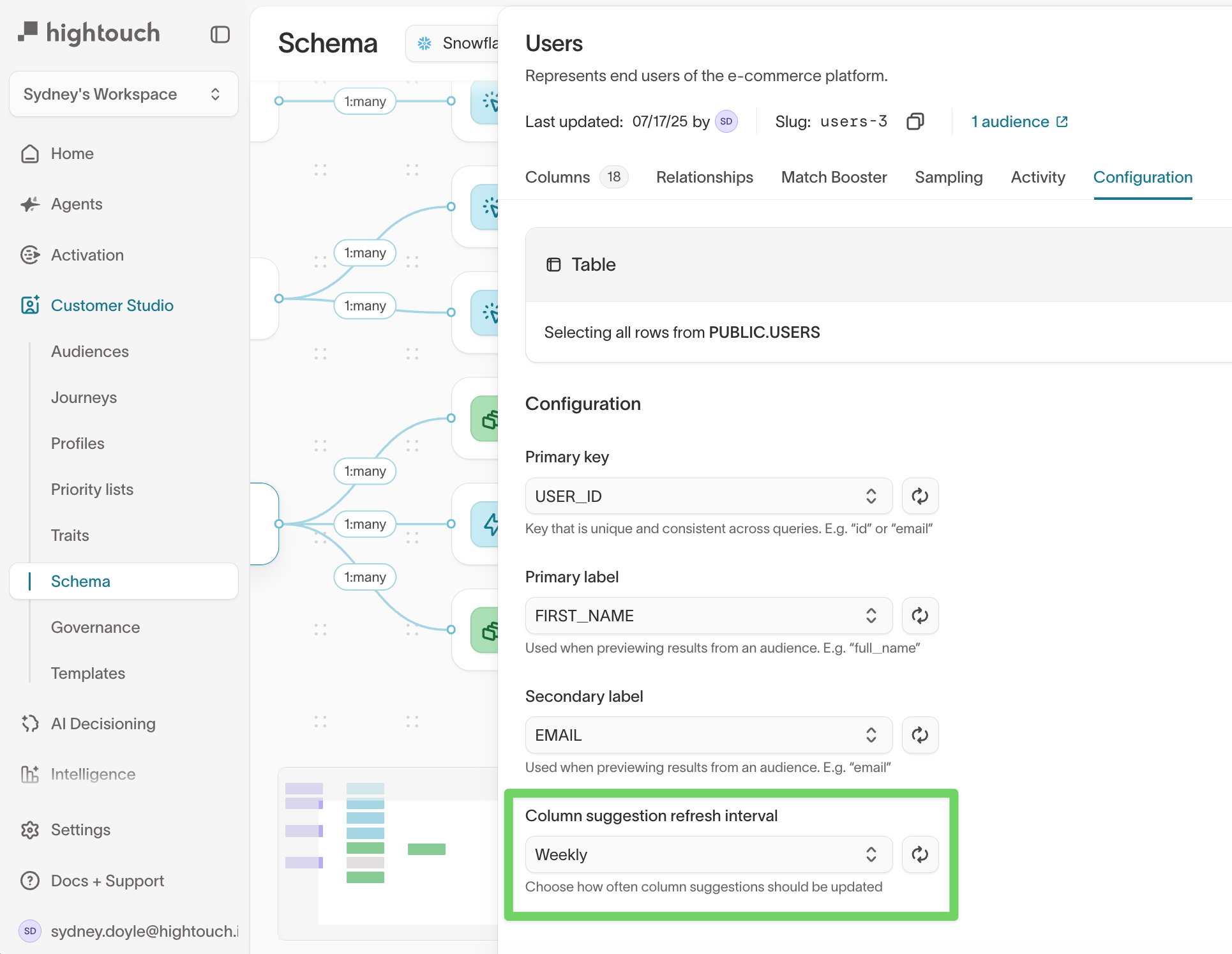
This setting controls how frequently Hightouch updates suggested dropdown values in the audience builder.
It does not affect:
- live audience results
- sync behavior
- warehouse queries (these always use your source-of-truth data)
Refreshing columns updates the fields and dropdown values shown in filters. It does not change your warehouse data or audience results.
What's next?
After defining your schema, choose the next step based on your role.
If you're setting up agents
Add warehouse tables that agents should be able to query but that don't belong in the audience schema:
- General models Make tables like sales data, product catalogs, or competitive benchmarks available for agent queries.
If you're managing governance and delivery
Set up rules that control how data flows to destinations and how consent is enforced:
-
Destination rules Define sync behavior, privacy policies, and delivery restrictions per destination.
-
Subsets Apply destination-specific filters (for example, opt-outs) without changing core audience logic.
-
OneTrust Snowflake Native App Enforce consent policies using Snowflake-native integration with OneTrust.
If you need reusable calculated values
If marketers need values that aren't stored as columns — like total spend, days since last login, or most frequent category — create them as traits:
- Traits Build reusable computed fields that appear in audience filters and sync field mappings.
For guidance on when to use a trait vs. keeping logic upstream, see When to model something as a trait.
If you're a marketer
Once the schema is in place, you can begin building audiences:
- Audiences Use filters, traits, and events to define dynamic segments directly from your data.