| Audience | How you’ll use this article |
|---|---|
| Data teams | Understand how identifier rules influence matching behavior and identity stability. |
| Platform admins | Debug unexpected merges or splits in resolved identities. |
Overview
Identifier rules control how records are grouped into resolved identities during identity resolution runs.
You configure these rules per identity graph to influence how records merge and when identities stay separate. They’re most useful when you want to:
- Validate that identities look correct
- Debug unexpected merges or splits
- Refine identity quality as your data evolves
Identifier rules work alongside your identifier mappings and model setup. They don’t clean data or introduce new identifiers, but determine how mapped identifiers are used during matching.
Prerequisites
Before configuring identifier rules, you must have:
Identifier rules are configured per identity graph and can only use identifiers that were mapped during graph creation.
Where to find identifier rules
To view or edit identifier rules:
- Go to Identity Resolution.
- Open the identity graph you want to inspect.
- Select the
Rulestab.
If you have view-only permissions for the source, you can see these settings but can’t edit them.
How identifier rules affect matching
When Identity Resolution evaluates a record, identifier rules determine whether that record:
- Joins an existing resolved identity, or
- Forms a new identity
At a high level:
Identifier prioritycontrols which identifiers are trusted first when matching records.Limit values per profileenforces boundaries that prevent identities from growing too large or merging unrelated records.
Together, these controls balance coverage (linking related records) with accuracy (avoiding incorrect merges).
Identifier priority
The Identifier priority list defines which identifiers are eligible to link records and the order in which they’re evaluated.
In the UI, you’ll see rows like Match on email or Match on anonymous_id, which you can reorder from highest to lowest priority.
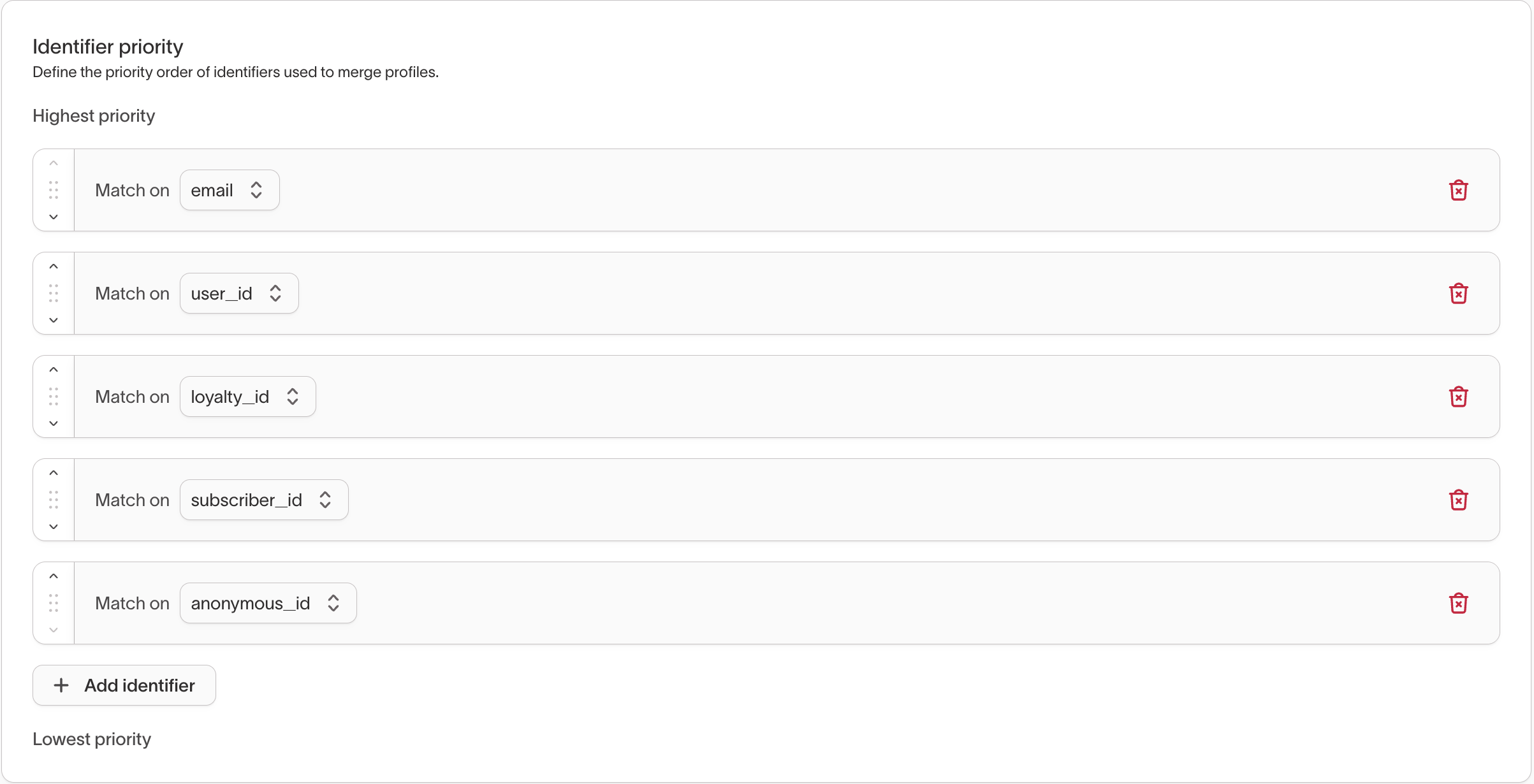
- Identifiers at the top of the list are treated as more authoritative.
- Lower-priority identifiers are evaluated only after higher-priority identifiers have been considered.
- Identifiers not listed are still recorded in outputs but won’t be used to merge records.
Identifier priority affects matching behavior only. It does not control Golden Record value selection.
You can add additional identifiers to the priority list by clicking Add identifier.
Only identifiers that were mapped during model configuration are available here. If an identifier does not appear in the dropdown, go to the Models tab in your identity graph and click Configure to assign it first.
Evaluate the most reliable identifiers first — for example, user_id > email > phone > anonymous_id.
Adjust ordering based on your data quality and business logic.
Limit values per profile
Limit rules define how many distinct values of a given identifier an identity is allowed to contain.
Each limit rule specifies:
- An identifier type (for example,
email,user_id,anonymous_id) - A maximum number of values per identity

Limit rules help you:
- Prevent over-merging caused by shared, recycled, or low-quality identifiers
- Enforce business constraints (for example, one
user_idper person) - Keep identities usable for analytics and downstream activation
Limit rules are often used to enforce business constraints (for example, one user_id per identity or one CRM ID per account).
Start with conservative limits for authoritative identifiers and expand cautiously after reviewing match results.
Overly permissive limits can create superclusters — large identities formed by shared or recycled identifiers (for example, shared emails or placeholder IDs).
If you observe unexpectedly large identities, revisit identifier priority and limits before rerunning the graph.
How limits interact with priority
When a proposed merge would violate a limit, Identity Resolution uses identifier priority to decide what happens:
-
Higher-priority identifier limit violated
The merge is rejected, and the record remains in a separate identity. This prevents unrelated identities from collapsing together. -
Lower-priority identifier limit violated
The identity retains only the first N values (where N is the limit) for that identifier type. Additional values are ignored for matching purposes.
Identifiers not listed in Identifier priority are treated as lowest priority for these checks.
Example: how identifier priority prevents over-merging
Assume you’re resolving identities using email and anonymous_id, with the following records:
| Time | email | anonymous_id |
|---|---|---|
| 12:01 | — | ANON001 |
| 12:02 | — | ANON001 |
| 12:03 | john.doe@acme.com | ANON001 |
| 12:04 | — | ANON001 |
| 12:05 | — | ANON002 |
| 12:06 | john@dundermifflin.com | ANON002 |
| 12:07 | — | ANON002 |
| 12:08 | carl.smith@acme.com | ANON002 |
Configuration
- Identifier priority:
email(higher),anonymous_id(lower) - Limit rule: max 1
emailvalue per identity
Resolution behavior
- For
ANON001, all records share the sameanonymous_idand only oneemailappears, so they form a single identity (HT1). - For
ANON002, early records form one identity (HT5) withjohn@dundermifflin.com. - When
carl.smith@acme.comappears, merging would introduce a secondemail.
Because email is higher priority and exceeds the limit, the record is not merged and instead forms a new identity (HT8).
Resulting identities
| Time | ht_id | email | anonymous_id |
|---|---|---|---|
| 12:01 | HT1 | — | ANON001 |
| 12:02 | HT1 | — | ANON001 |
| 12:03 | HT1 | john.doe@acme.com | ANON001 |
| 12:04 | HT1 | — | ANON001 |
| 12:05 | HT5 | — | ANON002 |
| 12:06 | HT5 | john@dundermifflin.com | ANON002 |
| 12:07 | HT5 | — | ANON002 |
| 12:08 | HT8 | carl.smith@acme.com | ANON002 |
This example shows how identifier priority and limits work together to prevent unrelated people from being merged into the same identity.
IDs are assigned at the time the identity is first created and are not necessarily sequential
Common implementation patterns
While every dataset is different, many teams:
- Place stable internal IDs (for example,
user_idor CRM ID) at the highest priority - Place
emailbelow internal IDs - Place device or
anonymous_idlower to prevent cross-user merging - Apply strict limits to authoritative identifiers (for example, max 1
user_idper identity)
Treat these as starting points and adjust based on your data quality and business model.
When to revisit identifier rules
You may want to review or adjust identifier rules if you notice:
- Unexpected identity splits
- Lower match rates than expected
- Overly large identities (superclusters)
- Activation issues caused by shared identifiers
After making changes, rerun your graph and review results in the Summary and Profiles tabs before activating downstream data.
Next steps
- Learn how matching works end-to-end in Deterministic identity resolution.
- Configure Golden Record for a one-row-per-identity view.
- See how to query and use outputs in Lookup table usage.