
If you’ve ever looked for an alternative to Segment, there’s a good chance you’ve stumbled across RudderStack. It’s an open-source version of Segment that specializes in event tracking. This blog post will cover the following:
- What is RudderStack?
- Core Products and Capabilities
- The Difference Between RudderStack Cloud and Open-Source
- Data Collection
- Data Storage
- Data Modeling
- Audience Management
- Reverse ETL
- Security
- Pros and Cons
What is RudderStack
RudderStack is a customer data infrastructure solution designed to help your data teams collect events, manage ETL pipelines, and build audience cohorts. The platform acts as a customer data pipelining tool to help you move data between systems.
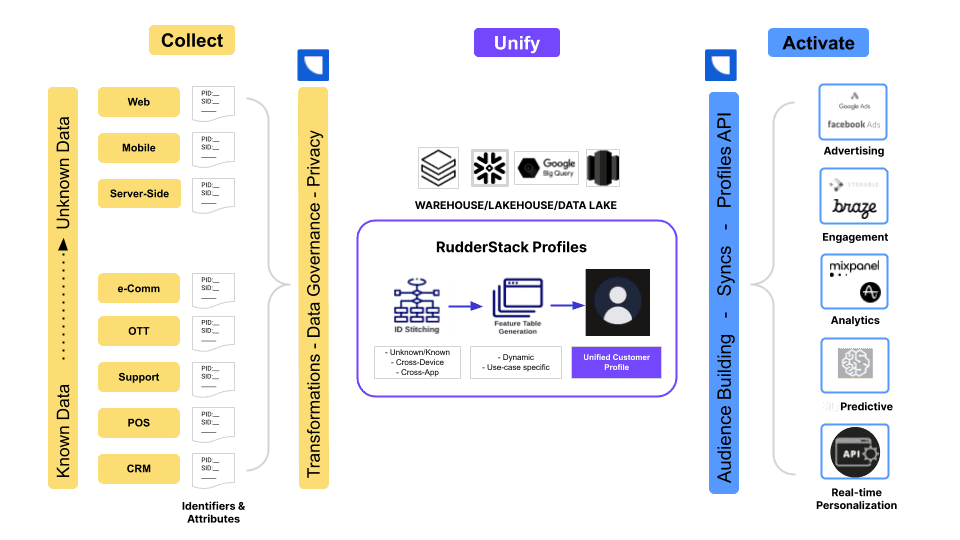
RudderStack was founded in 2019 by Soumyadeb Mitra as an open-source, low-cost alternative to Segment for event collection. Since then, the company has added a number of capabilities and repositioned itself as a warehouse-native CDP. The platform is designed for technical users who want a reliable platform to manage and activate the customer data living in their data warehouse.
While RudderStack was originally developed as an open-source solution, the company has since introduced several “premium” features to try and crack into the customer data platform space. These features are locked behind RudderStack’s Cloud offering.
RudderStack Quick Guide
Don’t have time to read our blog post? Download this one-pager on RudderStack for the key information.

The Difference Between RudderStack Cloud and Open-Source
There are two core components to RudderStack: the data plane and the control plane. The data plane is the back-end infrastructure that acts as the core engine for processing and routing events, and the control plane acts as the front-end UI, where you can define what events you want to capture. For the open-source version of RudderStack, you can deploy the data plane on Docker, Kubernetes, or a specific database that you define using the Developer Machine Setup. You can self-host the control plane locally to manage your data pipelines by exporting or importing your configurations as JSON files.
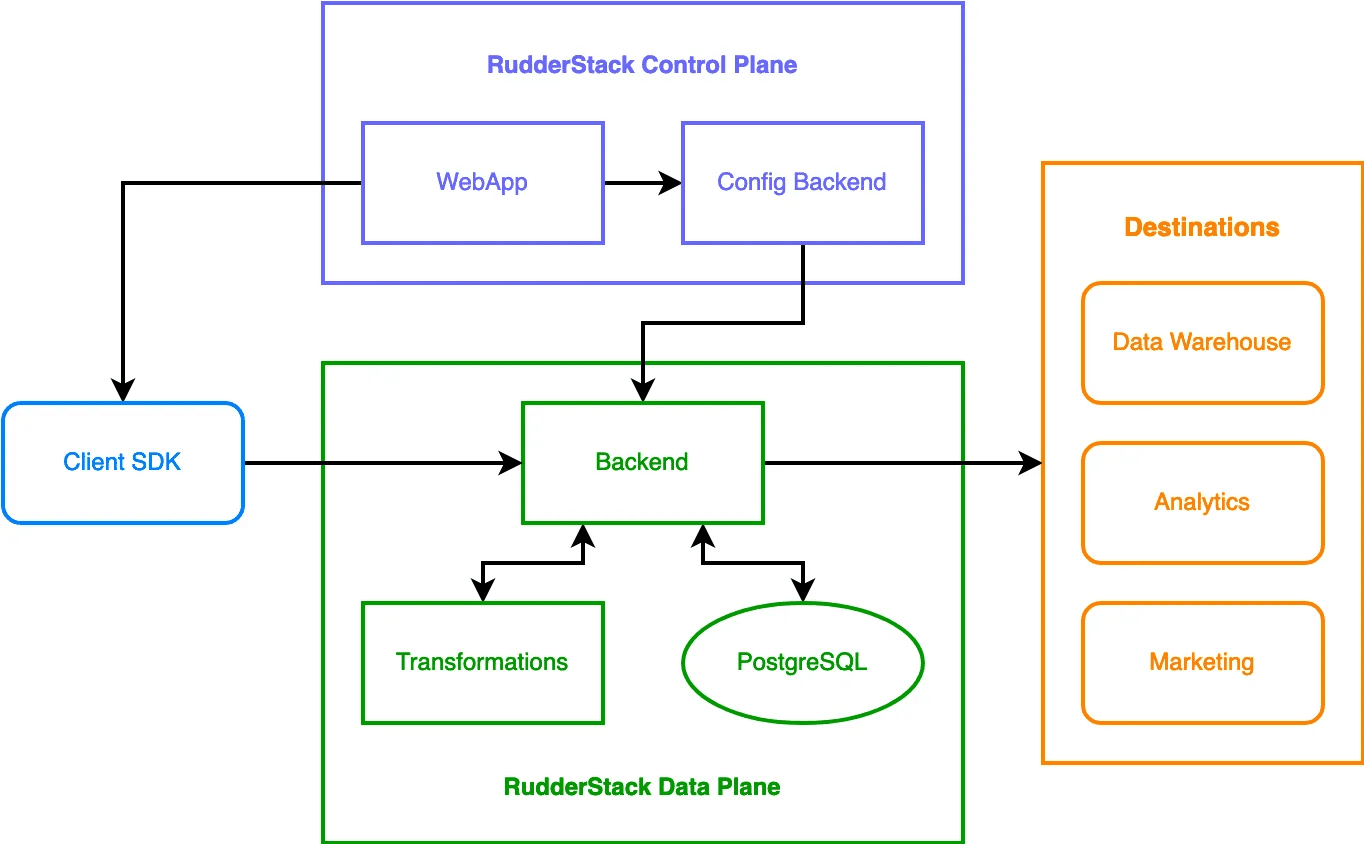
The cloud version of RudderStack is much more versatile and gives you access to wider capabilities. Whereas the open-source version is solely limited to event collection, the cloud-hosted version of RudderStack gives you access to all of the other products and capabilities that RudderStack offers. There’s also an added benefit because you don’t have to manage or maintain the infrastructure. However, this version of RudderStack is not free, which is one of the main reasons many companies choose to run RudderStack using their own infrastructure.
Core Products and Capabilities
While RudderStack originally started as an open-source platform, the company has branched out quite drastically since its inception in 2019, but the depth of functionality in the platform has not progressed at the same rate. The platform now offers five core products:
- Event Stream is RudderStack’s event-tracking solution, which lets you leverage SDKs to capture behavioral events across your websites, mobile apps, and servers and then route them to downstream operational tools or your data warehouse.
- Cloud Extract (ETL) is another data integration tool that RudderStack offers, but this solution is focused on helping you move data from your SaaS applications directly to your warehouse.
- Identity Stitching is RudderStack’s solution for helping you merge and combine unique identifiers across digital touchpoints so you can deduplicate known and anonymous users and create a standard identity graph in your data warehouse.
- Reverse ETL is RudderStack’s offering to help you move data out of your warehouse. This can include data ingested via event streams or ETL. The purpose of this tool is to help you federate data to all of the operational systems in your martech stack.
- Audiences is a feature available in RudderStack to simplify their Reverse ETL product. It gives you a no-code UI where you can build and create cohorts of users or customers directly from your data warehouse and then sync those audiences to your chosen destination.
Data Collection
RudderStack has two core capabilities for data collection: traditional ETL pipelines and event streams. If you want to capture events using RudderStack, the platform offers a number of software development kits (SDKs) that you can deploy directly on your website, mobile, app, or server. RudderStack offers both client-side and server-side tracking, so you can choose how to deploy these SDKs.
You can send events directly to RudderStack to transform them before you send them to your destination using the Cloud mode capabilities, or you can leverage the Device mode capabilities and sync data directly from the source to the destination.
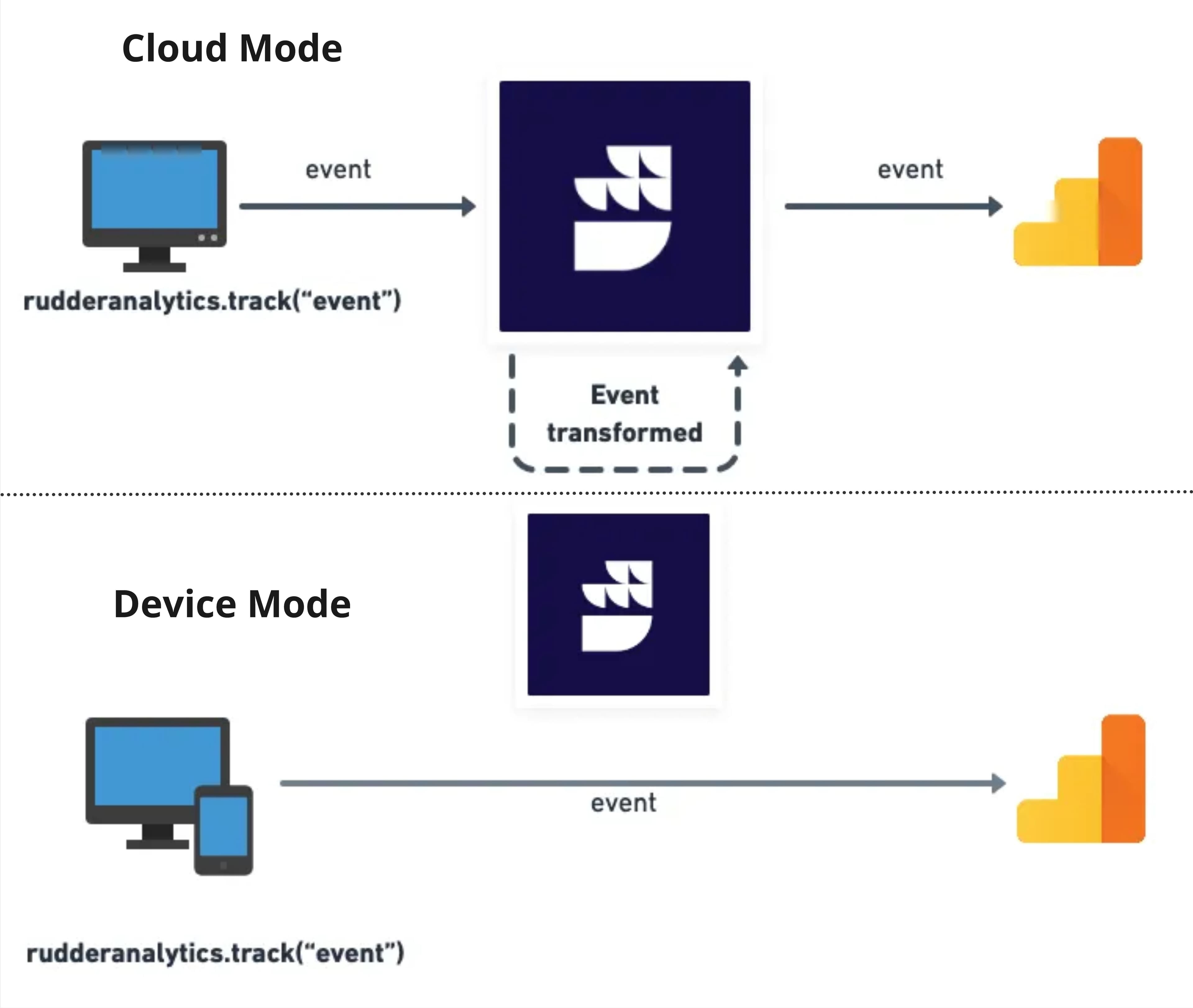
For non-event data or traditional ETL use cases where you need to move data out of your SaaS applications and load it into your warehouse, RudderStack offers a very limited number of sources compared to a traditional ETL vendor like Fivetran or Stitch. Additionally, if you want to create multiple ETL syncs from the same source, RudderStack forces you to create multiple sources for each sync.
Data Storage
With the default deployment of RudderStack, your event data is stored in a RudderStack-managed storage bucket on a seven-day rolling basis. If you’re an enterprise customer, you can change this to a 30-day rolling basis, or you can also choose to store these events in your own cloud storage solution. This data is largely kept for debugging purposes to capture sample events and responses and also processing errors and gateway dumps.
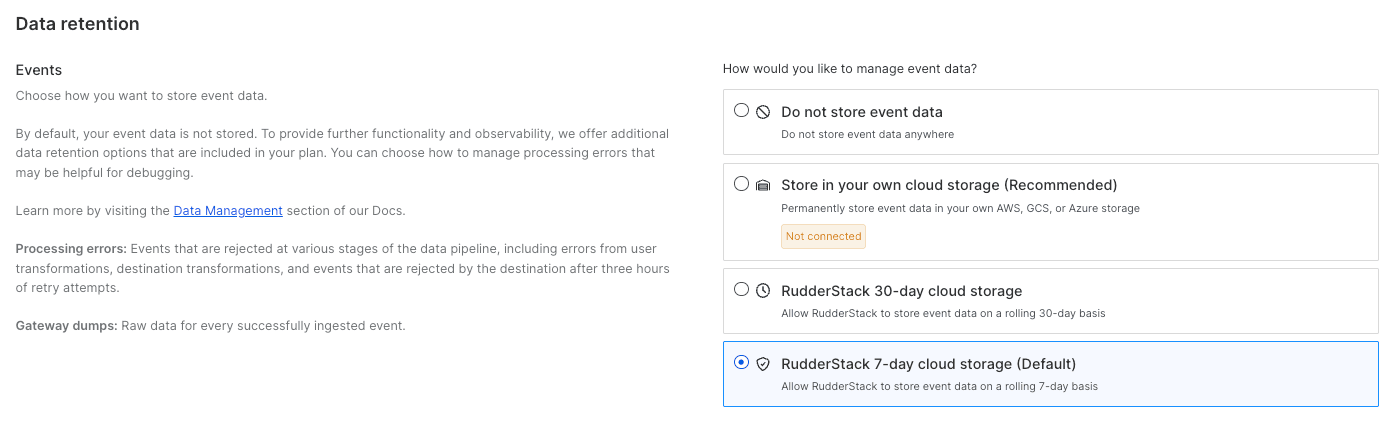
For all other aspects of RudderStack (e.g., audiences, identity resolution, Reverse ETL, etc.), you can plug directly into your existing infrastructure and leverage your existing data assets. RudderStack operates differently from a traditional CDP because the platform doesn’t actually store your customer data.
Data Modeling
Data modeling in RudderStack is relatively straightforward. The platform supports en-route transformations via custom Javascript and Python functions, so you can modify, filter, mask, clean, or enrich events before they arrive at your destination. Additionally, because RudderStack runs on top of your infrastructure, you own the schema, and identity resolution occurs directly within your warehouse.
Schema Management
RudderStack’s event tracking specs are almost identical to Segment's because the libraries were originally forked from Segment’s open-source libraries. RudderStack supports two event specs: Standard Events and E-commerce Events.
- Standard Events include the following API calls: Identify, Page, Screen, Track, Group, Alias, Merge, and Reset.
- E-commerce Events include the following API calls along with properties for each category: Browsing, Promotions, Ordering, Coupons, Wishlist, Sharing, Reviewing.
You can deploy tracking plans for each SDK to define exactly what events you want to capture and block to optimize your data quality. If you send events to your warehouse, RudderStack automatically generates a predefined schema for your event data. However, because the schema lives in your warehouse, you have full control to adjust it as you see fit.
Identity Resolution
If you want to build and manage customer profiles and power Customer 360, RudderStack has a feature called Profiles, which you can use to run transformation jobs in your warehouse to stitch customer data together from multiple sources.
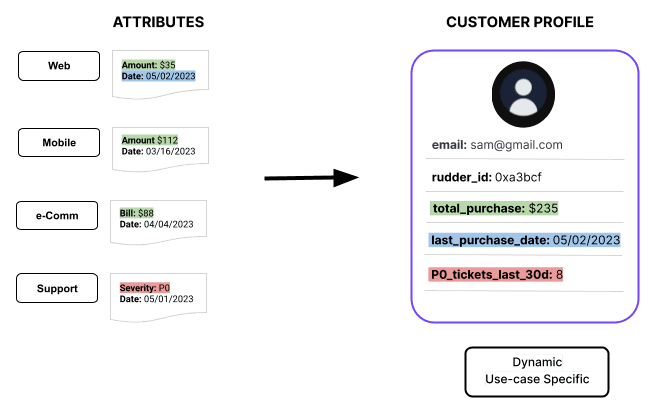
If you need to merge and resolve known and anonymous user profiles with identity resolution, RudderStack has a feature called Identity Stitching. This product helps you tie all your known and unknown IDs into a single table and link them using a standard RudderID.
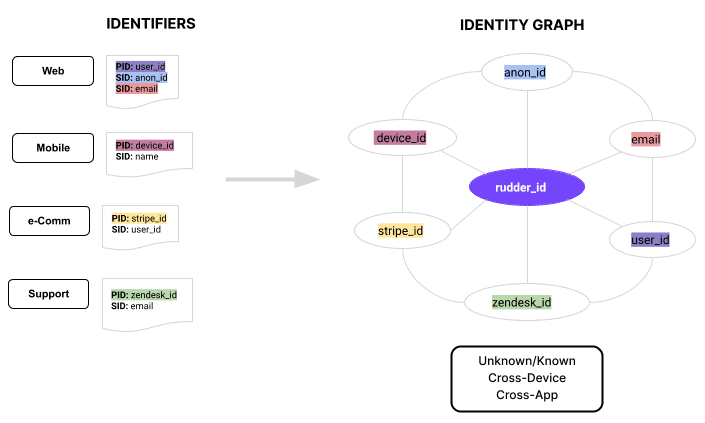
The benefit of this product is that you can own and manage your identity graph directly in your data warehouse. The downside to this approach is that RudderStack’s identity resolution algorithm is very limited and inflexible, only supporting deterministic matching and no and/or rules. Composable CDPs like Hightouch are more flexible because you can leverage multiple resolution rules and fuzzy or exact matching, all in a simple and easy-to-understand UI.
Audience Management
RudderStack also provides a no-code audience builder for your non-technical users that connects directly to your data warehouse. This feature allows you to build audiences off your data warehouse visually without writing SQL or code and sync audiences directly to your desired destination via Reverse ETL.
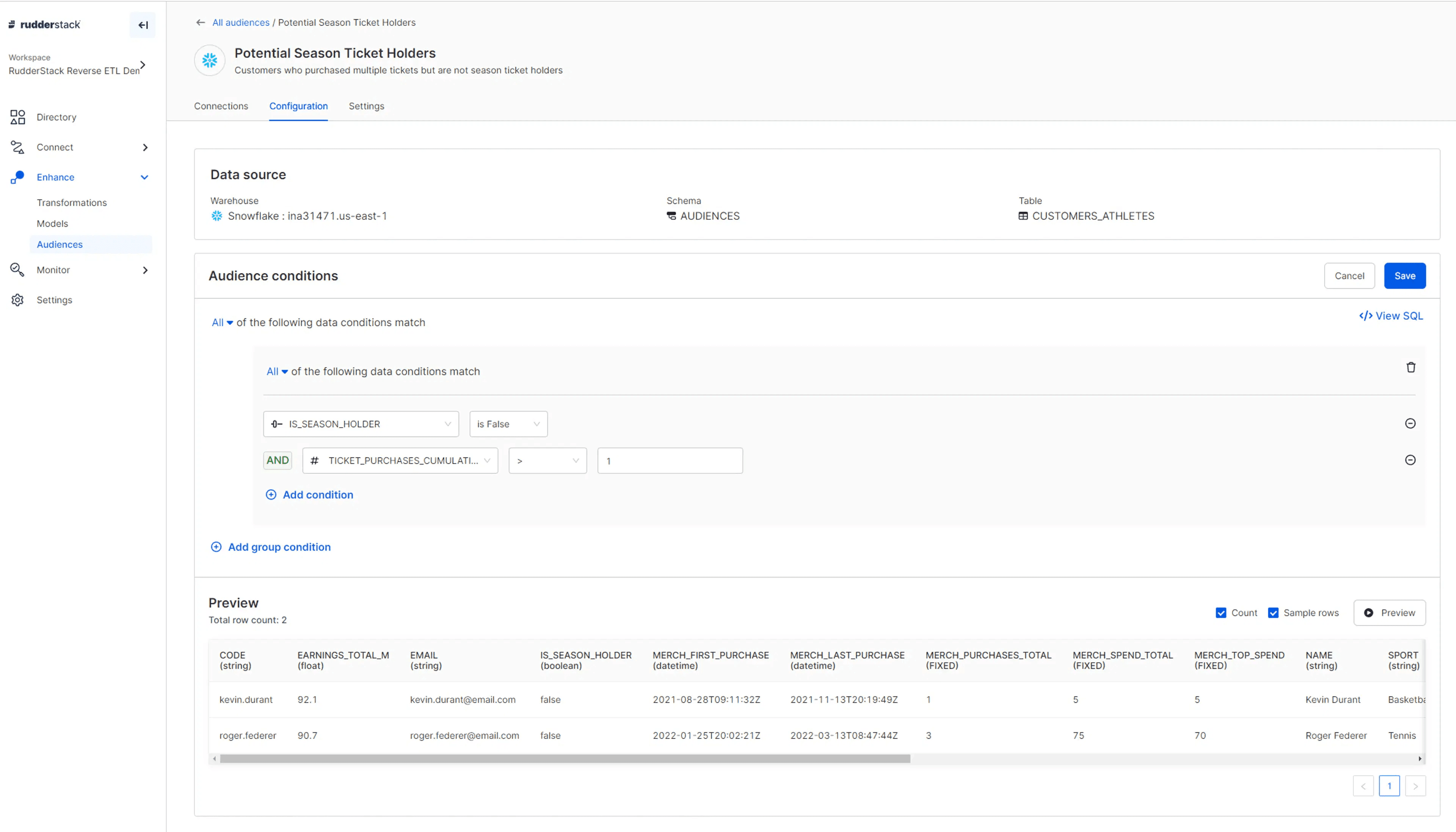
However, this feature is only available for Growth and Enterprise plans, and it supports a very limited number of destinations. The solution is very underdeveloped compared to other enterprise CDP and Composable CDP solutions. For example, if you want to build audiences, you’re limited to one table in your warehouse. This makes it nearly impossible to leverage any related models or events because you have to merge them in your warehouse first, which means you have to do a lot of engineering work to get value out of the audience builder.
Real-time Capabilities
While the standard for what it actually means to be “real-time” differs from company to company, RudderStack only supports two real-time features: Event Forwarding and Activation API.
Event Streaming lets you route client-side or server-side events directly to your destination without going through your data warehouse, and you can transform these events through RudderStack before they reach your destination. Once you’ve set up this pipeline, you can view all of your event streams directly in RudderStack to monitor events flowing into your destination and debug any potential errors.
Activation API works by syncing customer data from your warehouse to a Redis instance with an endpoint that instantly allows you to pull data into your chosen destination automatically. This feature enables your marketers to pull 1st-party data and customer attributes in real-time on an ad-hoc basis to power personalization across channels.
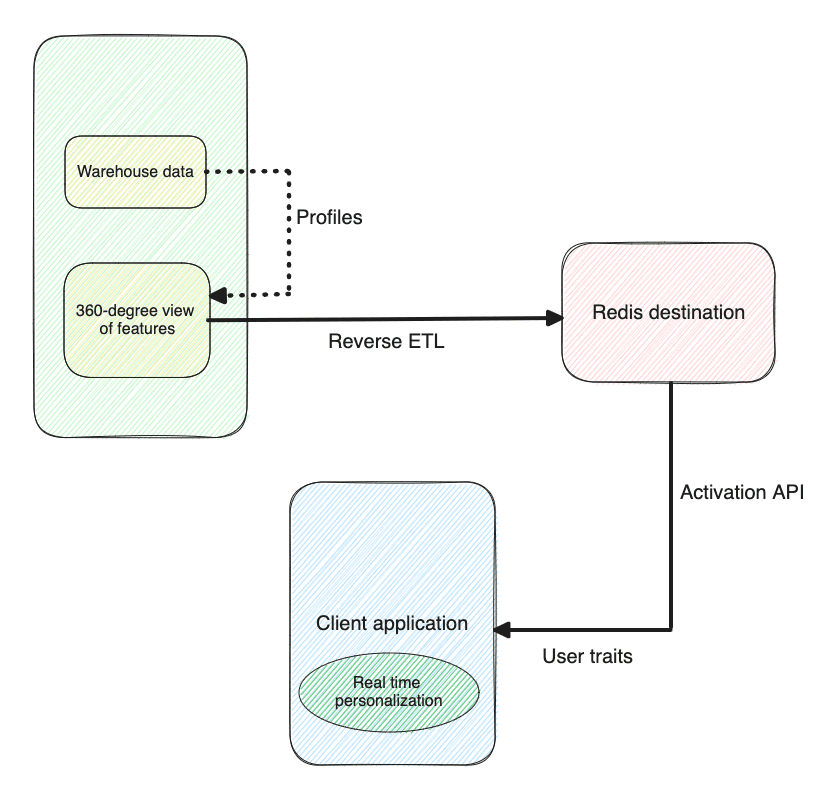
Note: other real-time features like Streaming Reverse ETL are not currently available within RudderStack, so if you want to stream tables directly in your warehouse, this will not be possible.
Reverse ETL
RudderStack does offer some Reverse ETL capabilities to move data out of your warehouse and sync it to downstream destinations, but the product is very limited because RudderStack’s core capabilities revolve around event collection. Within RudderStack, you can set your data warehouse or data lake as a source and sync data directly to your chosen destination.
The solution works very similarly to many other Reverse ETL tools, but there are a few major downsides to using RudderStack for Reverse ETL. Visual mapping (e.g., a UI for defining which columns from your model should appear in your destination) is only available for a select number of destinations, making the platform difficult to use if you’re not super technical.
Many destinations are also not leveraging bulk API endpoints, which can result in many problems for SaaS tools that impose rate and API limits. Speed can also be a problem in RudderStack because it can take several minutes for the average sync to complete and up to 10 minutes for sync metrics to update in RudderStack.
Security
From a security standpoint, RudderStack is a better option than many traditional CDPs because you can leverage your existing data storage solutions. The platform can meet HIPAA and GDPR requirements. You can take advantage of single sign-on (SSO) and deploy SSH tunnels to ensure your data is encrypted in flight.
For workspace management, you can set up role-based access controls (RBAC) to manage user permissions across your workspaces. The platform also gives you access to audit logs so you can track user activity directly in your app and easily monitor workspace changes in real-time. Within RudderStack, you can also set up both development and production workspaces so you can test and debug your pipelines before launching them in production.
Pros and Cons
RudderStack’s open-source event collection product can be a great alternative to traditional CDPs like Segment, ActionIQ or mParticle. However, the platform simply does not offer all of the necessary components to be considered a CDP. With that in mind, here’s a short list of some of the biggest pros and cons of RudderStack.
Pros
Open-source SDKs
Can leverage your existing data platform for underlying storage
Supports ETL pipelines to ingest data in addition to event collection
Cons
Not marketer-friendly (built for data teams)
Audience builder is difficult to use
Identity resolution mapping/merging logic is inflexible & purely deterministic
Reverse ETL is limited & underdeveloped
2024 CDP Landscape Guide
Evaluating CDPs? Download our 2024 CDP Landscape Guide to learn how the top ten enterprise CDPs compare across the following:
- Products & Features
- Core Capabilities
- CDP Type
- Key Differentiator
- Company Direction

Closing Thoughts
RudderStack is trying to be a Composable CDP, but the reality is that the platform is more of an open-source infrastructure solution for event collection. The platform simply lacks the maturity to compete against other Composable CDPs on the market because the platform is tailored for technical developers who want to manage and deploy data pipelines. If you’re a marketer, you’ll struggle to extract value from the platform.
If you’re looking for a Segment alternative or a free, open-source event collection platform, RudderStack can be a great option. However, if you’re looking for a fully-fledged Composable CDP that is built for both data teams and marketing teams, you should check out Hightouch. If you’d like to learn more, book a demo with one of our solution architects today to see how we can help.

















