
Introduction
If you work in Martech, then chances are you’re either looking to purchase a Customer Data Platform (CDP) or migrate to a new solution. In either case, there’s a high likelihood that you’ve stumbled across mParticle in your evaluation.
As you evaluate CDPs, it helps to look beyond event collection and architecture alone. The real question is how quickly your marketing team can activate data across channels, run real-time personalization, and operationalize AI-driven decisions without heavy engineering lift. That’s why composable CDPs like Hightouch are increasingly becoming the standard for modern teams.
This blog post will teach you everything you need to know about mParticle, including:
- What is mParticle?
- Core Products and Capabilities
- Data Collection
- Data Storage
- Data Modeling
- Audience Management
- Real-time Capabilities
- Data Activation
- Security
- Pros and Cons
What is mParticle?
mParticle is a traditional Customer Data Platform (CDP) that specializes in mobile event collection, so you can easily capture behavioral events and activate customer data across hundreds of marketing channels and destinations without heavy engineering lift.
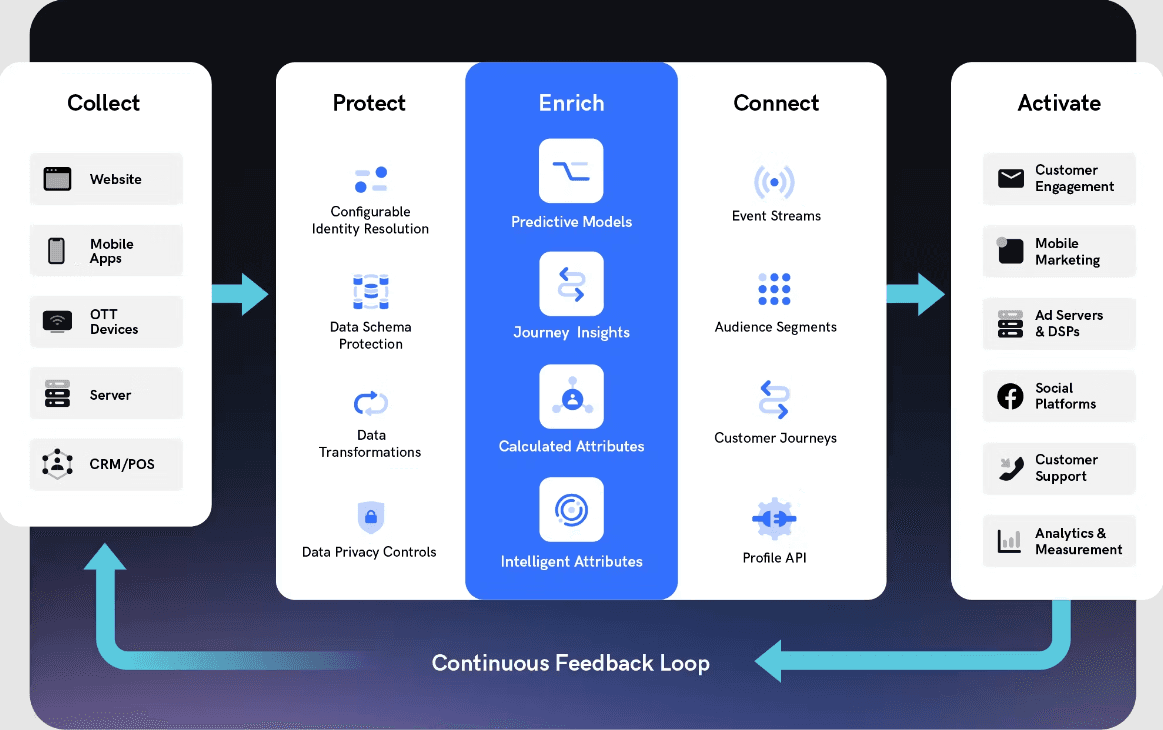
As a enterprise CDP, mParticle offers all of the bells and whistles of many other solutions in the market, including data collection, audience management, personalization, and some other real-time and even AI-based capabilities. The company was founded in 2013 with the goal of helping companies collect and manage data more effectively to drive personalization across channels.
It’s also worth distinguishing between AI features that generate predictions and AI systems that help teams consistently choose the best next action for each customer in real time. In practice, predictions only matter if you can operationalize them quickly across channels, iterate easily, and keep personalization running without heavy engineering lift.
mParticle rose to popularity as one of the earliest CDPs to specialize in mobile apps. In fact, if you look at mParticle’s customer page, you’ll notice a common denominator: many of the use cases focus on in-app personalization. The platform was initially created as an alternative to Segment for enterprise companies who wanted more security, better support, and flexibility. If you’re curious, there’s actually a really interesting thread on Quora from 2016 between the CEO of mParticle and the CEO of Segment comparing and contrasting their solutions.
mParticle CDP One Pager
Don’t have time to read our blog post? Download this one-pager on mParticle for the key information.

Core Products and Capabilities
While the mParticle platform is pretty versatile, you can break the company’s product offerings into five core categories.
- Data Connections is the backbone of mParticle’s CDP. This product lets you capture behavioral events from your mobile apps, websites, and servers and then push events directly to your marketing tools.
- Data Quality is the suite of tools that mParticle provides to help you manage what data you collect before you share events with your downstream systems. This feature set enables you to manage the schema structure of your data so you can build a cohesive data strategy.
- Data-Driven Personalization encompasses a variety of self-serve audience management features to help you build audience segments, calculated attributes, and even orchestrate customer journeys across your tools.
- Indicative is an audience analytics tool that mParticle acquired in 2022. This platform lets you perform cohort analysis across different audiences and also measure other key metrics like conversions over time. You can also further segment your users by specific events they performed to better understand exactly where they are in the customer journey.
- Cortex is an AI prediction tool that mParticle acquired through a company called Vidora. This feature enables you to build prediction-based models for your audiences, like churn risk, next best action, or even purchase propensity. These predictions can be powerful, but the real value comes from how easily marketers can operationalize them across ad, email, and in-product channels, and how quickly teams can iterate based on results.
Data Collection
mParticle provides out-of-the-box software development kits (SDKs) to capture both web and mobile data. You can deploy these code snippets directly on your website to capture behavioral events that you define. The platform supports multiple different SDKs, ranging from Node, Go, Python, Ruby, Java, etc., and also client SDKs like Android, IOS, web, etc.
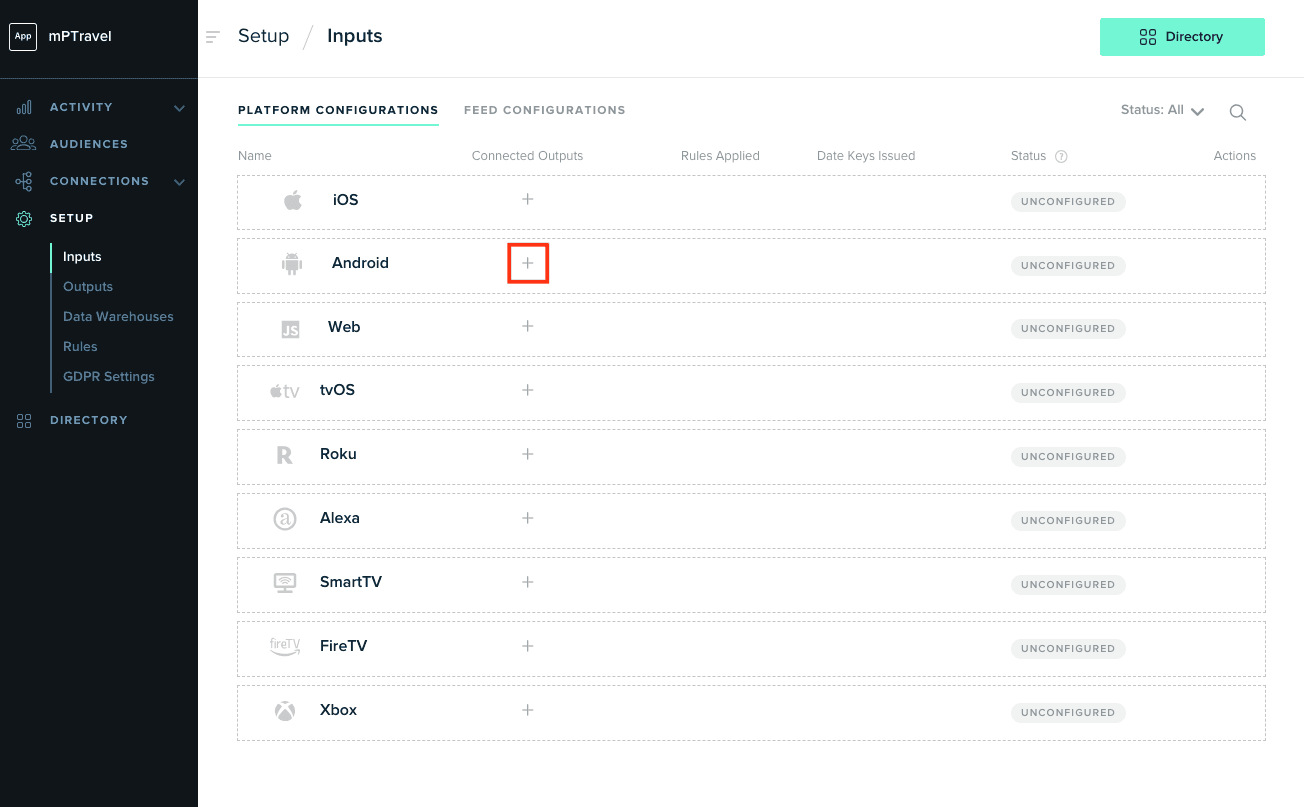
The actual data flow of mParticle is managed by input and output connections. Input connections ingest data into mParticle; output connections push that data back to your downstream destinations. From a tracking standpoint, the platform supports both server-side and client-side tracking. With server-side tracking, your data is forwarded from your web or client app to mParticle servers. Client-side tracking is the opposite; your data is forwarded directly from the point of origin to the output destination that you define. For example, in the image below, mParticle is syncing data to Amplitude from both the client-side and the server-side.
Within mParticle, you can collect two types of data: event data and user data.
- Event data refers to individual actions taken by a user in your app
- User data refers to unique identifiers (e.g., userID, email, etc.) or attributes to store custom values about your users.
You can also view six categories of events directly within the platform. This includes the following:
- Custom Events
- Screen Views
- Commerce
- User Information
- Application Lifecycle
- Consent
One of the downsides to this overall architecture is that you’re limited to behavioral data, which means you’re often missing the critical context that only lives in your cloud data warehouse. For marketers, that typically shows up as gaps in targeting and personalization, because key attributes like subscription status, lifecycle stage, predicted LTV, customer support sentiment, or product entitlements often live outside the CDP. Without that context, it becomes harder to build accurate audiences, trigger the right journeys, and deliver consistent omnichannel experiences. If you have custom data science models or enriched events for your customers living in your data warehouse, this problem only compounds, and trying to ingest those additional data sources into mParticle can create engineering challenges.
This is why many companies are choosing to implement Composable CDPs on top of their existing data infrastructure, so marketing can activate warehouse context directly, and even use AI decisioning to choose the right message, channel, and timing without needing engineers to constantly rebuild pipelines.
Data Storage
By default, all of your data is stored natively within mParticle. Because mParticle is a traditional CDP that operates on its own separate infrastructure outside of your technology stack, there are limits on how long you can store that data. This time duration is governed by your long-term data retention policy with mParticle.
For example, if your data retention for events is set to two years, you can view specific events that occurred up to two years ago. However, if the retention period for profiles is set to one week, any user who hasn’t interacted in the last seven days will be unavailable for your marketing team. mParticle offers unlimited lookback, but this premium feature is not available out of the box. This can be especially painful for marketing teams running longer lifecycle programs, win-back strategies, or seasonal analysis, since key audience logic may depend on history that falls outside the retention window.
With a Composable CDP, data lookback isn’t an issue because you have access to all of your data, not just clickstream data, and you don’t have to incur duplicative storage costs passed on by a CDP vendor. That’s the model Hightouch is built around, keeping the warehouse as the system of record so marketers can build audiences and personalization logic on the full history of customer data, while keeping implementation and maintenance lighter for technical teams.
Data Modeling
mParticle provides a number of capabilities for managing your data schema and performing identity resolution, but both of these features come with their own challenges.
Schema Management
For event collection data, mParticle has six industry-specific templates and one generic data plan you can use to define your data model. The JSON schema structure that mParticle defines the structure of all the data you send to mParticle, and the plans let you select what user and event data you want to capture. These six data plans include the following:
- Generic
- Travel
- QSR
- Gaming
- FinTech
- Retail
- Media
One important factor to remember is that mParticle’s default tracking plans are limited to 1,000 data points. Your data also has to conform to the schema structure that mParticle supports if you want to use it to build audiences and sync them to your downstream destinations. Any data that does not conform to mParticle’s schema structure cannot reliably be delivered to your destination.
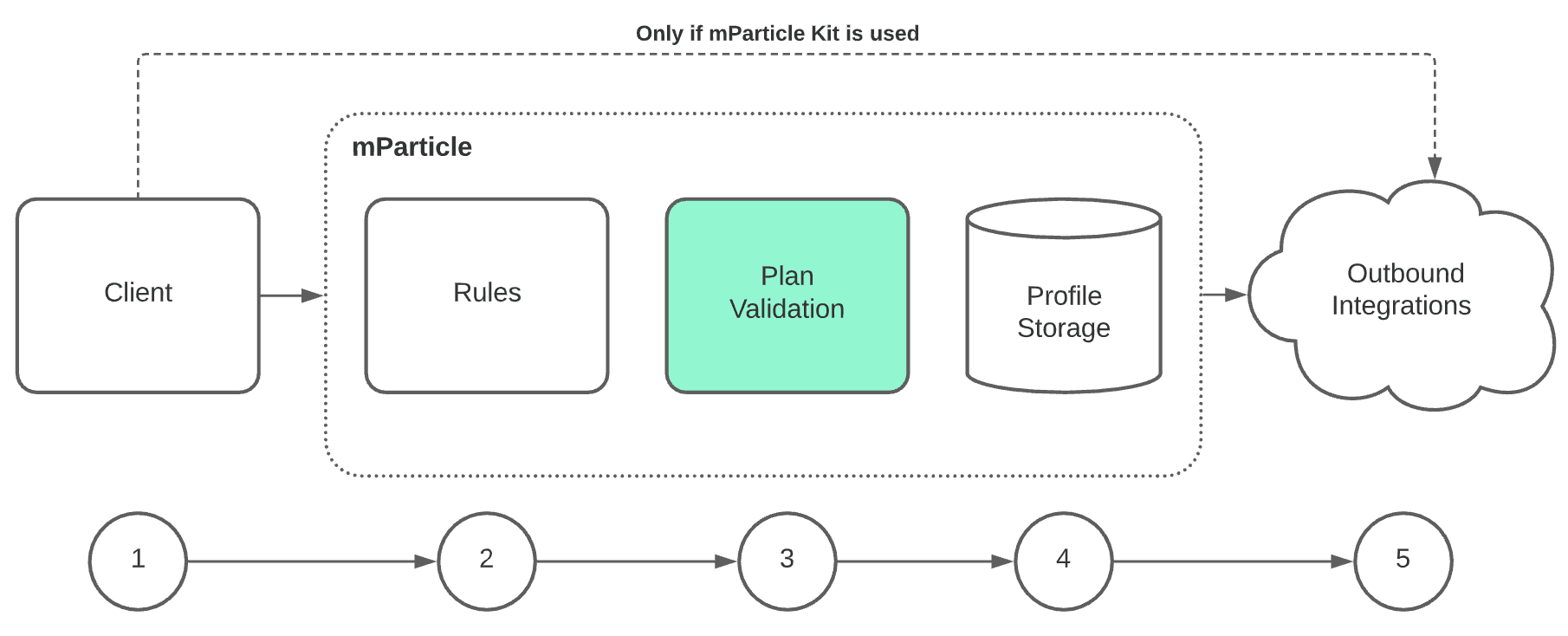
Traditional CDPs like mParticle require your data to conform to either a user or account object hierarchy. Depending on the complexity of your business, this can be a problem, especially if you need to support other custom entities or related models. This challenge is another reason companies prefer to leverage their existing infrastructure. Implementing a Composable CDP on top of your data warehouse gives you access to all of your existing data models because you own the schema structure. From a practical standpoint, this often translates into slower iteration for marketers. When the data model can’t support the entities that matter (subscriptions, accounts, products, locations, loyalty tiers), teams end up relying on workarounds, custom engineering, or rigid audience definitions that are harder to maintain over time.
Hightouch is built to be easy for both marketers and technical teams, letting marketing work with warehouse-defined models directly, rather than forcing data to conform to a vendor-specific hierarchy.
Identity Resolution
Underneath the data quality suite, mParticle offers two products for identity resolution: IDSync and ComposeID.
IDSync is mParticle’s core identity framework for building unified customer profiles. This feature is powered by an Identity API that pulls in all the known identifiers of a current user and then maps those identifiers to individual profiles. With IDSync, you can merge and deduplicate your known and anonymous user identities so you can deliver consistent experiences and identify users at specific points in their journey.
Currently, IDSync only supports deterministic matching to unify your profiles, which means you have no ability to leverage probabilistic matching. You also don’t have much flexibility to adapt this identity resolution algorithm to your specific needs because the API acts as a black box that offers little to no visibility. Another downside to IDSync is the fact that you don’t own the identity graph, which makes it very difficult to leverage in other use cases.
For marketers, the impact is straightforward: identity rules determine whether campaigns reach the right person with the right context. When the graph is opaque or lives outside your core data stack, it’s harder to audit, test, and apply identity logic consistently across all downstream tools.
Composable approaches typically give teams more transparency and control over identity logic, which helps marketing and data teams align on how profiles are built and how personalization is executed.
On the other hand, ComposeID lets you resolve unidentified user data and profiles directly within your data warehouse. However, to use this feature, you must enable Warehouse Sync (more on this in the Data Activation section below.) While this feature is more flexible than IDSync, it’s very underbaked and was built solely to appease the pent-up demand around “composability” as more and more companies want to own their identity graph and manage their identity resolution algorithms directly in their data warehouse.
Audience Management
Once your event data is available within mParticle, the platform’s audience management tools let you create segments of users or customers based on criteria that you define and then sync those audiences to your operational tools. You can aggregate behavioral data and store it as calculated attributes like lifetime value, last page viewed, average order value, last purchase, etc. mParticle also supports journeys, so you can deliver personalized experiences across channels and route customers down different paths based on their behavioral tendencies. When building these workflows, you can also split journeys based on milestones or actions that you define. For example, you may want to deliver a different experience to a shopping cart abandoner compared to a recent purchaser.
This is where many CDP evaluations are won or lost, not by the data architecture, but by how quickly marketers can build audiences, launch campaigns, and iterate on performance without relying on engineering. Platforms like Hightouch lean into this by combining composable data access with real-time activation and AI decisioning, so teams can move faster from insight to action.
For audience building, mParticle allows you to build two types of audiences: Real-time Audiences and Standard Audiences.
- Real-time Audiences are available to all mParticle accounts. This feature calculates audiences using your last 30-90 days of data, and they’re updated on an ongoing basis. However, these audiences are very limited because you don’t have access to the full range of data that lives in your data warehouse. Great for quick behavioral triggers, but limited when personalization requires warehouse context.
- Standard Audiences are not available by default. This is a premium feature that lets you build and define audiences using long-term historical data. With standard audiences, you can build segments using any data stored in mParticle. However, this feature limits you to a set number of calculations because the size is much larger. It can also take substantial time for audience calculations to be completed with mParticle, which is another reason why companies prefer Composable CDPs: they can leverage their own computing resources. Useful for lifecycle marketing, but slower calculations can limit experimentation velocity.
Real-time Capabilities
Real-time is an interesting topic because many companies have a different definition of what real-time actually means. mParticle offers two main solutions: Event Forwarding and Profile API.
- Event Forwarding allows you to sync events directly to your output destinations as they’re generated on the client side. This feature is useful if you need to leverage your events as soon as possible. However, one of the downsides to this approach is that the data is raw, and you don’t have the ability to enrich it or transform it before it arrives at your destination. With a Composable CDP, you can join and transform data directly in your warehouse before ingesting it into your downstream tools.
- Profile API is low-latency API that lets you query against mParticle so you can pull in rich customer profiles, attributes, and other data available within mParticle via an HTTP request. This feature enables you to power one-to-one personalization on an ad-hoc basis as you need the data. It supports unlimited queries per second with an average response time of 20 milliseconds. Keep in mind this feature is standard across all CDP and Composable CDP vendors, so it’s not exactly a unique selling point.
In practice, “real-time” matters most at the marketer decision layer, meaning the ability to evaluate context and choose the right next action (offer, channel, timing) while the customer is active, not just forward raw events immediately. That’s where Hightouch’s real-time activation and AI decisioning positioning is different, it’s designed to help marketers act on real-time signals with the full warehouse context behind them.
The real-time audiences within mParticle are “real-time” solely in the fact that they’re re-calculated as you generate new events, but syncing those audiences does not take place in real-time. Another important factor to note is that mParticle currently does not support the ability to stream from tables in your warehouse via Streaming Data Activation.
Data Activation
If you want to sync data from your warehouse directly to destinations, mParticle offers a feature called Warehouse Sync. This product enables you to leverage your own data infrastructure as a source and route data directly from your data warehouse or data lake to your chosen destination. However, this feature is very immature compared to other Data Activation tools, and it lacks a lot of critical features around observability and version control. The practical downside is that marketing teams may still need engineering support to manage changes, troubleshoot sync issues, and safely scale activation workflows as requirements evolve.
Additionally, given how new this product is to the mParticle arsenal, it’s very unclear how Warehouse Sync integrates with all the other features the platform provides. Given that mParticle was originally designed to operate as a packaged CDP, it’s probably safe to assume that there are some compatibility issues pairing Data Activation with other features like audiences or analytics.
Security
Since mParticle is a traditional CDP, your data will always be stored in the platform unless you rely solely on the Warehouse Sync feature. The good news is that this data is encrypted both in-transit and at-rest. The platform also offers a number of features to manage user access and permissions via role-based access (RBAC). Features like single sign-on (SSO) and multi-factor authentication (MFA) are also available within the platform. While the platform can be GDPR, CCPA, and HIPAA compliant, you must do some heavy engineering work in the actual implementation to be compliant.
Pros and Cons
If you’re looking for a traditional and packaged CDP, mParticle can be a great option. However, if you want to own your data structure, unlock greater flexibility, and leverage all of the customer data in your warehouse, only a Composable CDP can do that for you. With that in mind, here is a short list of pros and cons for mParticle:
Pros
Strong for mobile-first personalization and event routing
Marketer-friendly UI for basic segmentation and journeys
Includes predictive modeling features via Cortex (Vidora) and audience analytics via Indicative
Cons
Inflexible data model and schema requirements (limited support for custom objects and entities)
Activation is limited without warehouse context, which can restrict advanced marketing use cases
Harder for marketers to self-serve complex personalization without engineering support
Prediction tooling exists, but AI decisioning and continuous experimentation workflows are less native
Identity graph is owned by mParticle
Long implementation and difficult setup process
Data is stored outside of your cloud infrastructure
2024 CDP Landscape Guide
Evaluating CDPs? Download our 2024 CDP Landscape Guide to learn how the top ten enterprise CDPs compare across the following:
- Products & Features
- Core Capabilities
- CDP Type
- Key Differentiator
- Company Direction

Closing Thoughts
If you have no data footprint, a traditional CDP like mParticle is a great way to start powering personalization. However, if you already have customer data living in your warehouse, adopting mParticle will simply introduce duplicative storage costs and added complexity as your data team will be forced to manage two sources of truth.
For teams that already operate from the warehouse, Hightouch is designed to make activation and personalization easier and faster. As a composable CDP and AI platform built for marketers, it helps teams launch and maintain campaigns, audiences, and AI-driven decisioning workflows without heavy SQL or constant engineering support. If you’re evaluating CDPs and want an enterprise-ready solution that’s fast to implement and efficient to maintain, book a demo to learn more.

















