
Data warehouses have been batch-based since their inception in the 1980s. With modern platforms like Snowflake, BigQuery, and Databricks, these batches have become faster, cheaper, and easier than ever. But fundamentally, data warehouses are still batch-based! Data transformation and activation pipelines often run on a recurring schedule and reprocess data during each run.
This paradigm is starting to change. Recent innovations like Snowflake’s Dynamic Tables, emerging players like Materialize, and new methods for warehouse change data capture (CDC) are pushing the cloud data warehouse away from batch and towards a streaming data future.
Today, we’re thrilled to share a new technology that leverages these capabilities to activate data faster than ever: Streaming Reverse ETL.
Streaming Reverse ETL syncs data from the warehouse at extremely low latency and unlocks new high-speed use cases, such as abandoned cart campaigns, conversion events, onboarding emails, lead routing, and more. Streaming Reverse ETL is warehouse-native and works with your existing data, without copying or caching.
In the blog ahead, we’ll dive deeper into how traditional Reverse ETL works, how Streaming Reverse ETL is different, and how we’ve built the fastest-ever sync engine using new warehouse features.
How Reverse ETL Works and Why Data Latency Exists
Reverse ETL 101
Reverse ETL syncs data from your company’s data warehouse to downstream tools like CRMs and marketing platforms. Today’s leading Reverse ETL solutions share several fundamental characteristics:
- Deliver new data, updates, and deletions. When underlying data in the warehouse is added, changed, or removed, Reverse ETL passes these changes to downstream tools. This delivery can take a few different forms. New data can be added in each tool as new rows or entries, but Reverse ETL also supports use cases where you’d update, resync, or remove existing records.
- Declarative. Declarative means you specify what data in your warehouse you’d like to sync and how you want it to appear in your downstream tool–the Reverse ETL platform does the rest. You shouldn’t need to think about the underlying API calls.
- Abstract integration complexity. Reverse ETL removes all the effort it would take for data teams to build and maintain custom data pipelines to third-party tools. At Hightouch, we’ve built an extensive integration catalog of 200+ data sources and destinations. We constantly maintain APIs and endpoints for each of these integrations.
- Only sync changed data. To operate efficiently (for speed and cost), Reverse ETL must figure out what changed in the warehouse and sync only the new information to downstream tools. Figuring out what’s new is called change data capture (CDC). Without CDC, Reverse ETL would have to sync entire tables every time, which is not only slow but also cost and scale-prohibitive.
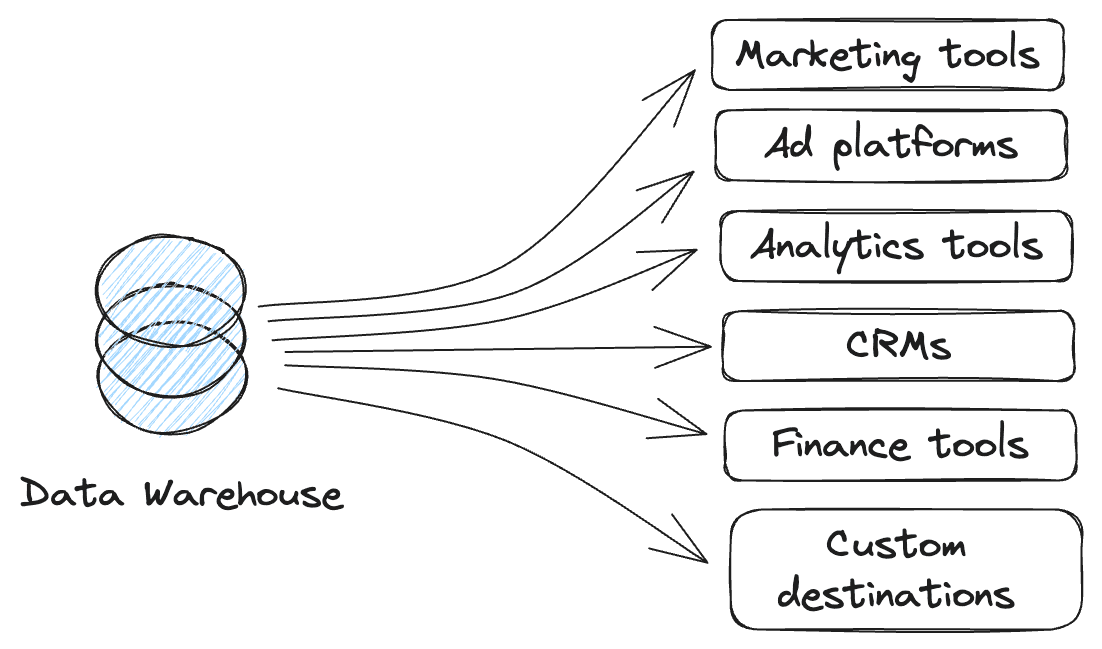
With the help of Reverse ETL, modern data teams embrace the warehouse as the center of gravity for their business operations. This architecture is powerful because it centralizes analytics and activation in the same place.
Traditional Reverse ETL pipelines have two sources of potential latency that can prevent certain high-speed use cases, however: (1) time spent on data transformation and (2) time spent on change data capture (CDC).
Data Transformation Takes Time
Most data pipelines are batch-based. After ingesting raw data into the warehouse, teams perform a series of transformations—for example, cleaning data, building user profiles via identity resolution, and calculating business metrics like lead scores and LTVs. These processes typically run on recurring schedules, executed in batches. With the rise of cloud data warehouses like Snowflake and Databricks, data teams have progressed from nightly jobs to hourly jobs at many companies. However, as transformation pipelines grow in complexity, latency becomes a growing concern: you can’t activate data at a faster frequency than its underlying transformation jobs.
Change Data Capture Takes Time
To build a scalable Reverse ETL platform, you need to detect changes in warehouse data efficiently and only sync those changes instead of performing a full refresh during every run.
Most transactional databases like PostgreSQL and MySQL have native changelogs that essentially emit a feed of row-level change events as they happen. (These changelogs form the backbone of database replication tools and most ETL platforms like Fivetran and Airbyte.) Unfortunately, until recently, many popular data warehouses did not have native changelogs, or they had CDC features incompatible with how data teams expected to build their batch-based data pipelines.
Reverse ETL vendors overcame this problem with an alternate process for CDC called “diffing.” Instead of using the warehouse’s native changelog, diffing compares every row of data against a snapshot taken during the previous run to see which ones have been added, changed, or removed between runs. Diffing is more compute-intensive, and, as you can imagine, it takes longer than native CDC.
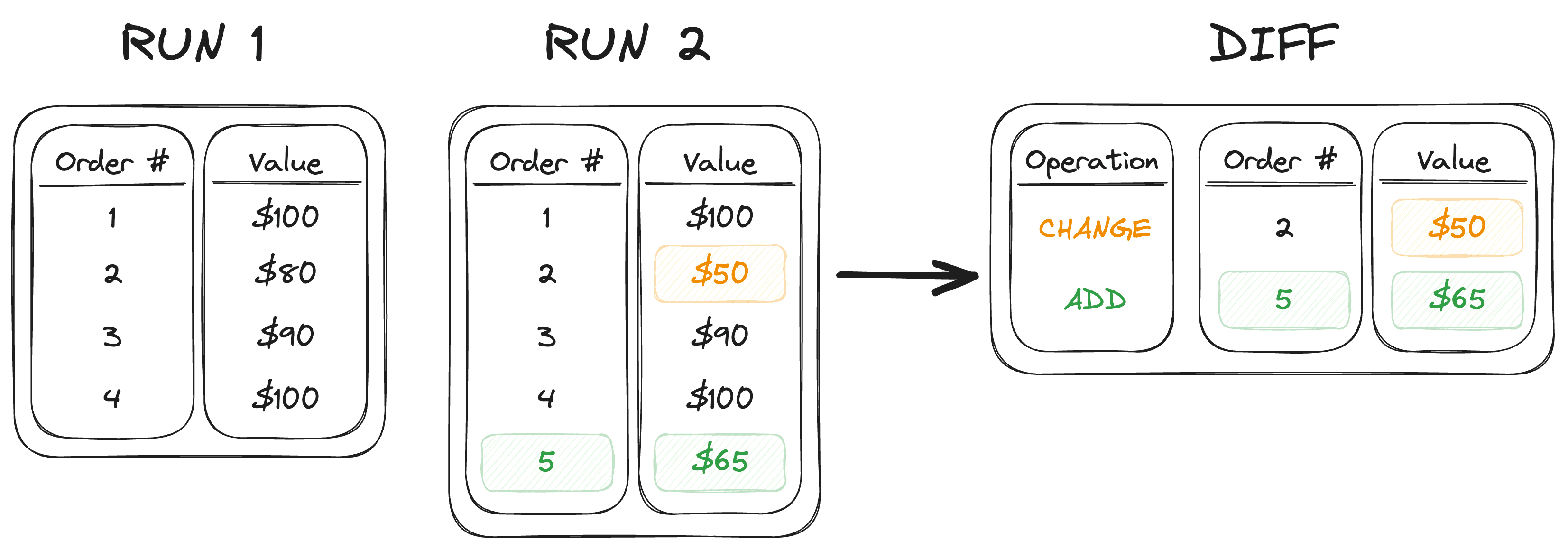
Diffing takes a variable amount of time that depends on the size and complexity of the underlying data model. For small amounts of data—or from basic, append-only tables—diffing takes mere seconds. But for large enterprises syncing hundreds of millions or billions of rows, diff calculations can take several minutes or longer.
The result is that batch-based data modeling, coupled with diff-based CDC, introduces a delay between the moment that data is written to the warehouse and when Reverse ETL can deliver it to downstream tools. This delay renders some real-time use cases infeasible.
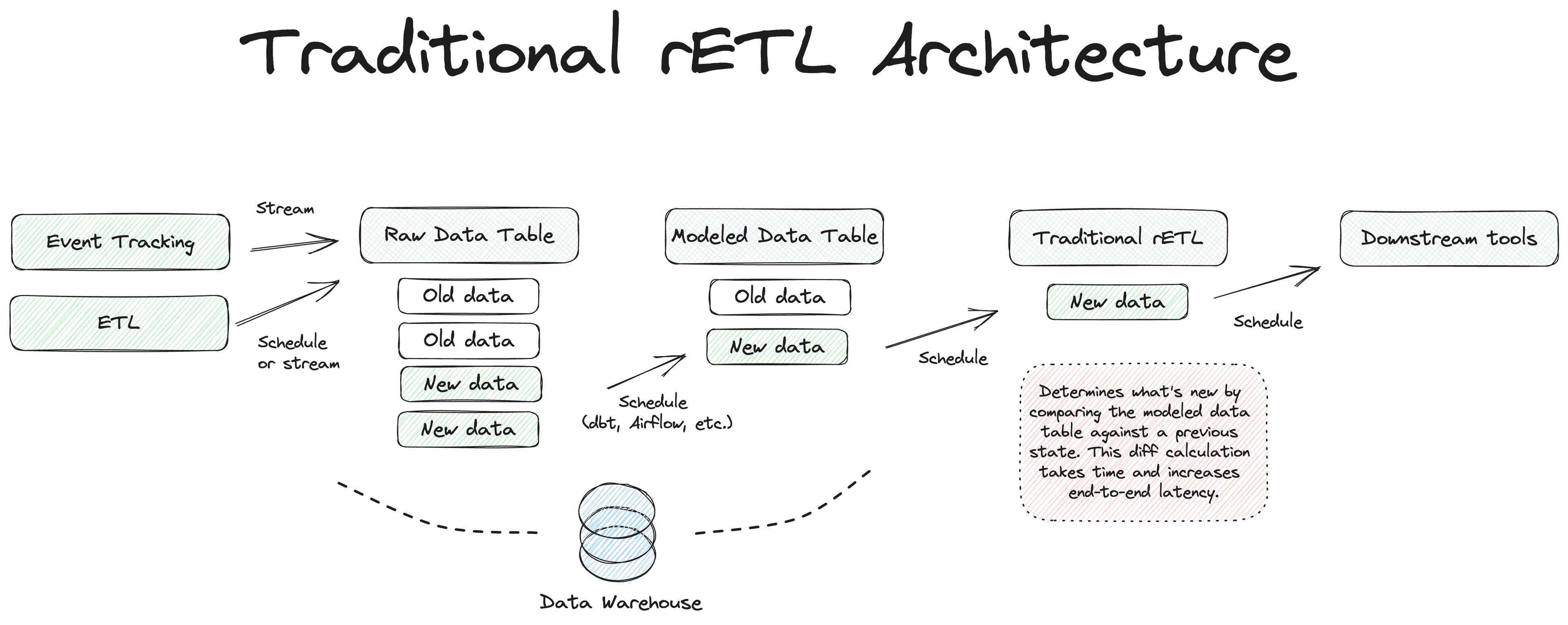
So, if we want to improve end-to-end latency, we must rethink our architecture. Luckily, new data warehouse capabilities have helped us address both sources of latency, changing how data transformation happens in the warehouse and eliminating diffing.
Streaming in the Warehouse and Reverse ETL
Streaming Tables Simplify and Speed Up Data Modeling
A new approach, which we’re calling “Streaming Tables,” makes it possible to model data in a continuous stream as it enters the warehouse. Snowflake's Dynamic Tables are leading this trend, and other data warehouses like Databricks are also building their own Streaming Tables. This method allows data engineers to simply declare the end state for their transformed data using SQL. The warehouse processes new data incrementally and continuously to materialize query results in the end table. Data teams no longer have to schedule transformations in batches or worry about dependencies between their different pipelines
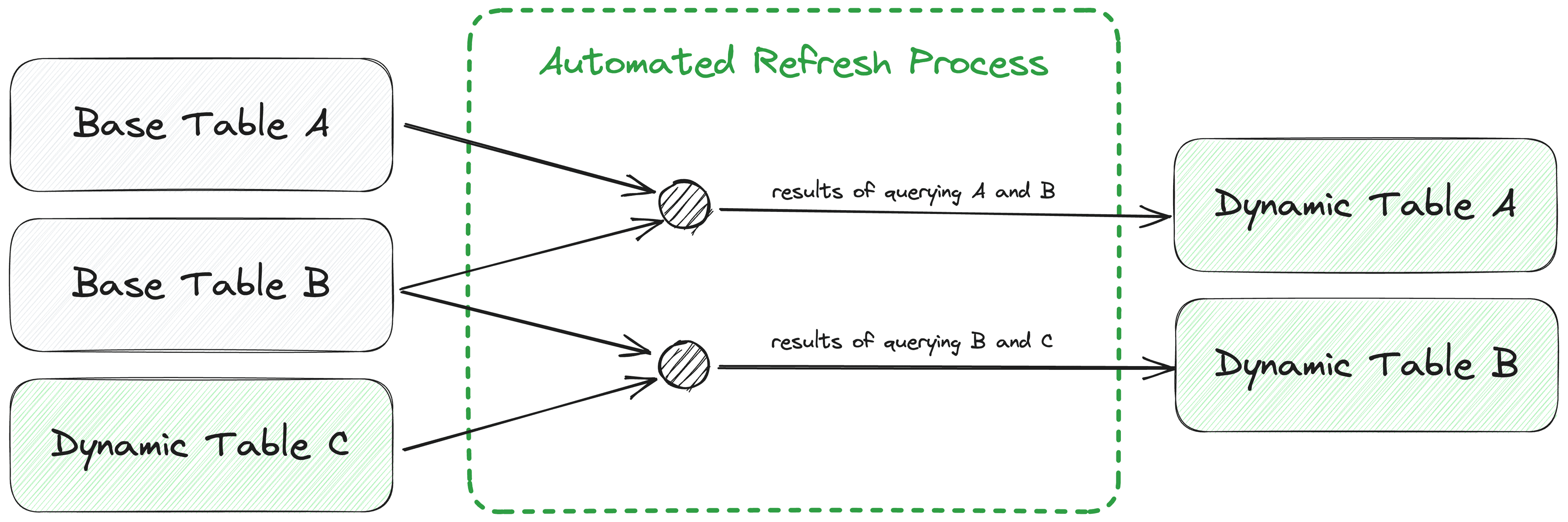
Snowflake’s Dynamic Tables update continuously with new data
Streaming Tables help overcome the first source of latency in Reverse ETL: time spent on data transformation. With this first latency source addressed, we next turned to diffing delays in Reverse ETL.
Introducing Streaming Reverse ETL
Streaming Reverse ETL maintains Hightouch’s declarative interface and other features, but it completely re-architects our sync engine to remove the costly overhead of performing diff calculations during every run.
With Streaming Reverse ETL, you don’t need to set a recurring schedule to sync your data to your downstream tools. Streaming Reverse ETL is “always on” and streams new data continuously as it reaches a Streaming Table. Our sync engine no longer calculates diffs from discrete runs; instead, changes are promptly observed and synced downstream as they happen.
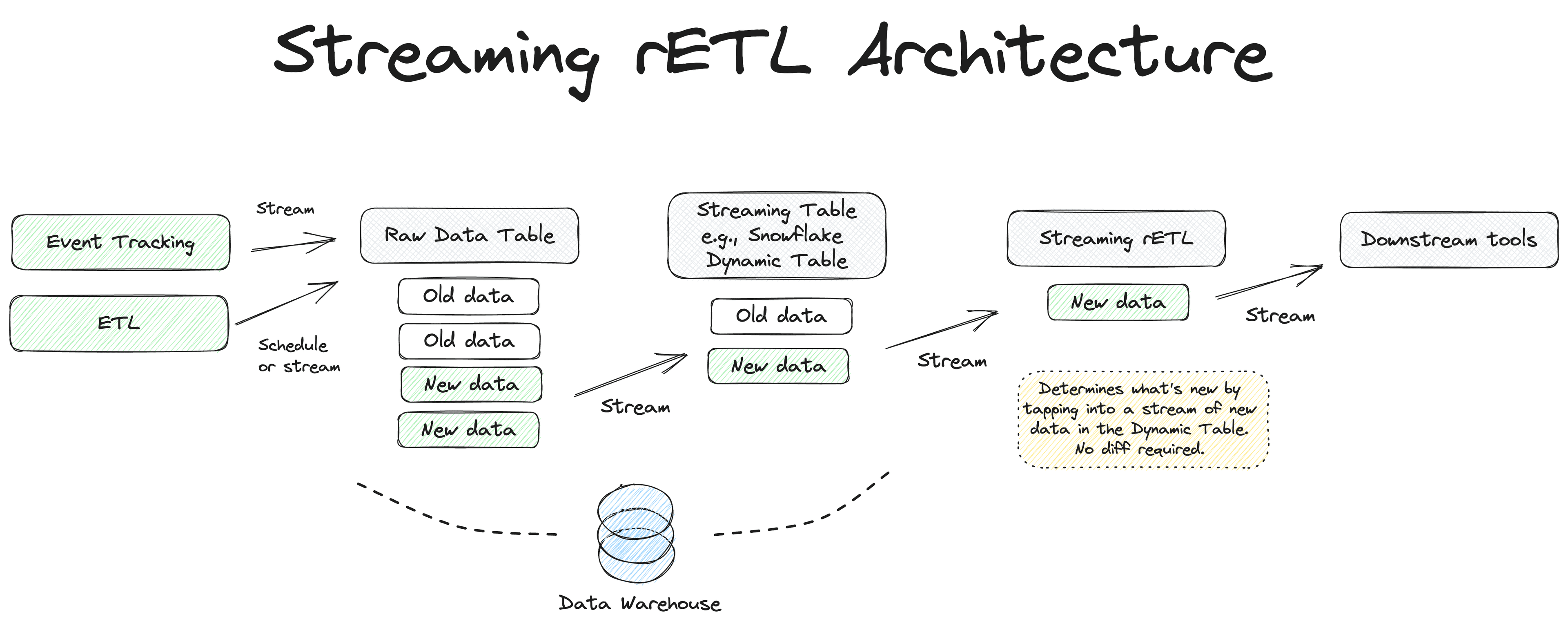
Together, the combo of data modeling with Streaming Tables and data activation with Streaming Reverse ETL unlocks high-speed use cases like triggering transactional emails, sending timely operational alerts, and enriching events before forwarding them to different destinations.
Streaming Reverse ETL from raw tables with streams has a latency on the order of seconds end-to-end. This covers most simple use cases around real-time data--for example, responding to analytics events tracked from your website with something like Hightouch Events or Snowplow or Kafka streams with Snowpipe Streaming.
Streaming Reverse ETL from fully transformed Streaming Tables like a "golden users" table might take a bit longer--currently, Snowflake’s Dynamic Tables have a minimum target lag of 1 minute, though this will improve. We’re excited to work with our warehouse partners to make Streaming Reverse ETL even faster as the technology matures.
We’re En Route to the Real-Time Composable CDP
While we’re starting today by shipping Streaming Reverse ETL, we’re just beginning our journey to support high-speed use cases from the data warehouse. Streaming Tables open up opportunities to perform continuous transformations, such as identity resolution, and provide the basis for faster audience building and customer analytics.
Hightouch is building the Composable Customer Data Platform (CDP) centered on the data warehouse. With these innovations, the Composable CDP will increasingly support real-time needs for customer data. Streaming has been one of the last barriers blocking some marketing teams from using the warehouse to power their operations–so we’re thrilled to share these innovations that will make the warehouse more useful than ever.
Streaming Reverse ETL is available today for Snowflake, with other sources coming soon.
Book a meeting with our solutions engineers to try out Streaming Reverse ETL or to discuss the future of streaming in the warehouse. We couldn’t be more excited!

















