
This June, bombshell news rocked the data world: Databricks acquired Tabular, a lakehouse startup from the founders of Iceberg, for $2B after an apparent bidding war with Snowflake.
Even before this acquisition, data communities had been abuzz with advances in the open-storage format Apache Iceberg. Just two months before the Tabular acquisition, leaders at both Hightouch and Orchestra weighed in on the trend, predicting that the rise of Lakehouse will revolutionize SaaS and data engineering by decoupling compute and storage.
Still, Iceberg adoption is hypothetical at many companies. The obvious question is: when should you seriously examine your tech stack and consider migrating? What are the possible benefits, and when is it worth the effort to change your data infrastructure?
In this blog, we’ll briefly recap the benefits of Iceberg and discuss what you should consider when exploring it for your organization.
What is Apache Iceberg?
Apache Iceberg is an open-source table format for managing large datasets in data lakes. Iceberg doesn’t directly define how your data is stored (that’s what file formats like CSV and parquet do) but defines how data gets organized logically, like a blueprint for structuring and accessing data efficiently. Another similar table format is Databricks’ open-source Delta Lake format.
Iceberg is exciting because it offers high-performance data warehousing features for object storage like S3. Therefore, Iceberg opens up a future where companies can use their own object storage like a data warehouse. Iceberg was developed at Netflix and is now used by many large companies, including Bloomberg, Apple, LinkedIn, and Airbnb.
For a deeper introduction to Iceberg, check out this blog.
Benefits your organization can get from an Iceberg Lakehouse
Improve performance and reduce costs by separating compute and storage
Iceberg decouples data storage and query computation. This reduces costs and improves operations, allowing companies to store data cheaply, and pay for compute as needed. If you maintain your storage layer in Iceberg, you can swap in any query engine (Trino, Spark, Snowflake, etc.) for any unique workload. This architecture, frequently called the lakehouse, is essentially a “composable data warehouse” made of separate storage and compute layers.
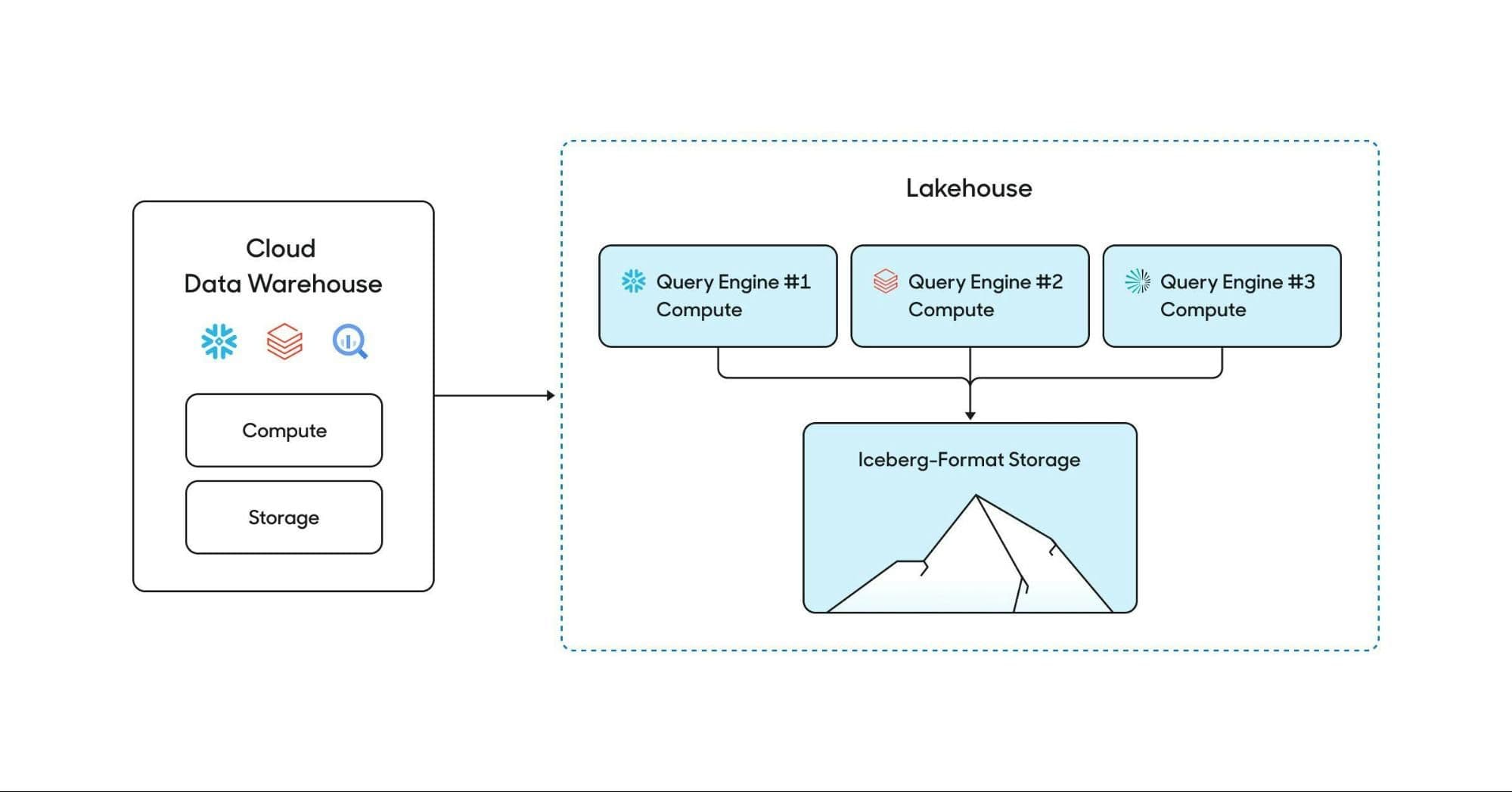
Companies can decouple compute and storage in a Lakehouse.
By definition, each query engine performs tasks differently. Some are better than others at different projects— which is why, for example, you’ll see enterprises using both Snowflake and Databricks. The problem with using both Snowflake and Databricks for different workloads is that you have to move the data back and forth between these platforms. Iceberg offers a future where there's no movement necessary— all these compute engines could simply connect to a unified storage layer.
Choosing the most efficient query engine for each task will not just improve performance: it will also allow companies to save on total compute costs and negotiate between competitive query engines for better prices.
Improve security by keeping data in your environment
Most data warehouses like Snowflake and BigQuery historically required you to “import” data into them to use their query engines (and store data in their table formats). This results in data leaving your cloud environment.
Now, with vendors like Snowflake and Databricks supporting table formats like Iceberg and Delta Lake, companies can keep data inside their cloud environment and bring query engines to that environment.
More efficient data ingress, egress, and processing
Iceberg table formats allow you to store data in your own object storage (such as S3) rather than a data warehouse hosted by a third party. Generally speaking, it’s easier and more cost-efficient to manage data ingress, egress, and processing in object storage, especially for streaming data. You can also avoid hefty data egress fees that object storage providers like AWS charge, since you no longer need to copy data into a data warehouse.
It’s not a coincidence that Iceberg started at Netflix, which has massive amounts of real-time data, and that early adopters have been huge enterprises like Apple and LinkedIn. These companies have a volume of streaming data that makes data warehouses unappealing compared to object storage, and Iceberg is the best way to manage data in object storage.
Iceberg migration considerations
All right, so you know what Iceberg is and how it can help your organization in theory. But what about in practice? How should you evaluate the cost vs. reward of this substantial undertaking?
For a start, proof-of-concepts are critical. Iceberg is in an “early adopter” stage, so you’ll need to evaluate critically whether it can perform for your company’s specific use cases and whether the performance improvements are worth the effort of migration.
Here are some of the key areas to evaluate:
Does Iceberg provide the performance you need?
A key consideration for enterprise data architects is evaluating the functionality and performance of an Iceberg-centric architecture. Proprietary table formats and proprietary SQL engines are made for each other, like a Ferrari’s engine fits perfectly in a Ferrari chassis.
It’s almost undeniable that an open table format won’t have the same functionality as a mature data warehouse. There may also be differences in performance for comparable workloads. You should POC your critical existing data warehouse workloads in an Iceberg format.
Does Iceberg support your transformation integrations?
You should evaluate Iceberg compatibility with data transformation providers in your data stack. Transformation frameworks like dbt will likely support functionality on Iceberg piecemeal (not all at once). Today, you can use dbt in Iceberg via query engines like Glue and Trino, but features in these packages may be different or limited compared to ones in major data warehouses like Snowflake. There might be functions (for example, dbt clone) that are not natively supported in Iceberg.
Similarly, other transformation partners are still new to the Iceberg ecosystem: for example, Coalesce.io announced support for Iceberg tables via the Coalesce engine only recently.
You need to ensure that Iceberg supports your key data transformation workflows before migrating.
How will you move data into and out of Iceberg?
Companies typically use ELT tools such as Fivetran or Airbyte to move data from various sources to data warehouses. They may also ingest data to warehouses with streaming solutions like Kafka. You should evaluate these data ingest tools to ensure that they support your object storage as a destination instead of a data warehouse and that they can also write data into your Iceberg file format. Examples of vendors releasing support for landing data in Iceberg formats include Fivetran, Airbyte, Confluent’s TableFlow, and Upsolver.
Companies typically use Data Activation and Reverse ETL platforms like Hightouch to move data out of their data warehouses to power use cases like data-driven marketing, advertising, and operations. Luckily, Hightouch already fully supports Data Activation from Iceberg formats and allows you to bring your query engine of choice (such as Trino/Starburst) to maximize performance. Beyond just data egress, this becomes an even more exciting idea with Composable CDP. Hightouch can connect directly to an open data lake and provide marketing teams the ability to self-serve their own data for activation and personalization without any opinionated modeling or extra data movement.
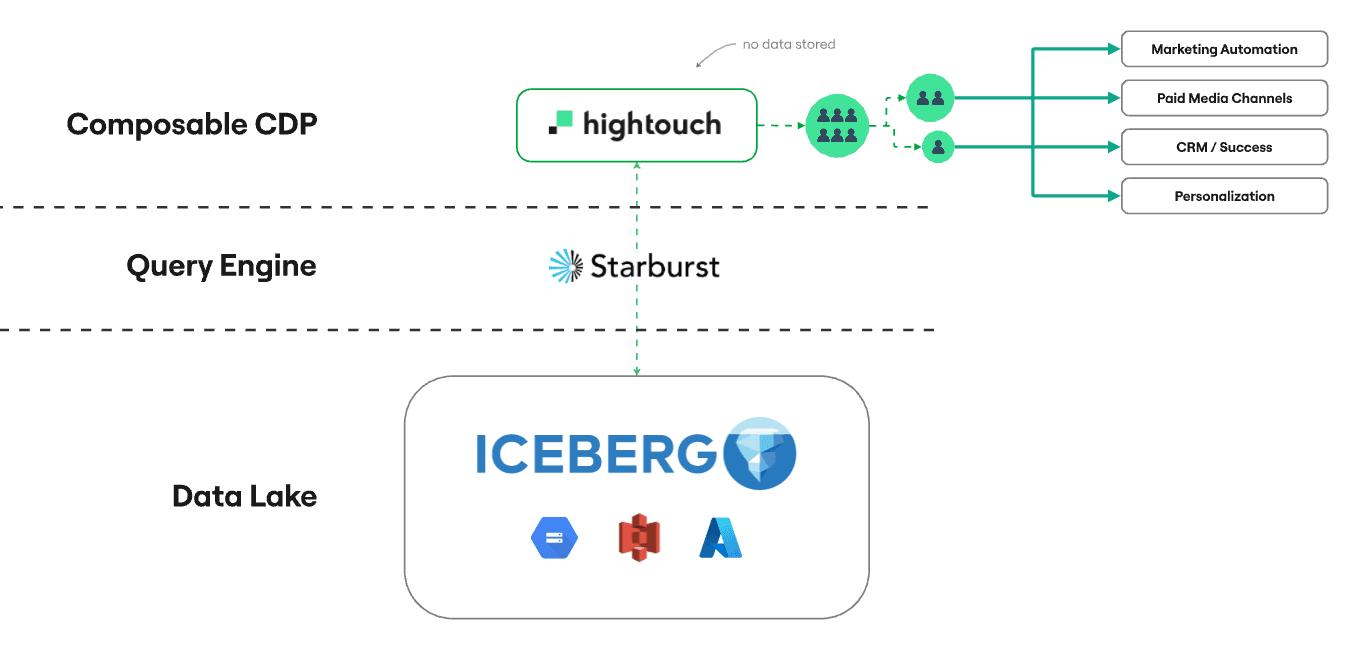
Sample Composable CDP architecture on a data lake in Iceberg format, using Starburst as a query engine.
How will you orchestrate multiple query engines?
One key benefit of Iceberg is your ability to bring different query engines to different workloads, increasing performance while reducing costs. In one example scenario, analysts would use Athena for ad-hoc queries; lighter company workloads could run on duckdb; heavier workloads could run on Spark.
This inherently introduces orchestration and networking complexity. You should assess whether your data team can handle this complexity in-house or with a dedicated orchestration platform.
For example, Orchestra has native, managed connectors that can help ease the pain of infrastructure integration and networking. You can use Orchestra to trigger queries in any of your query engines, monitor them, and then surface the results and any other helpful underlying metadata. This is helpful because then data teams can easily debug failures and identify the root causes of them from a single place inside Orchestra.
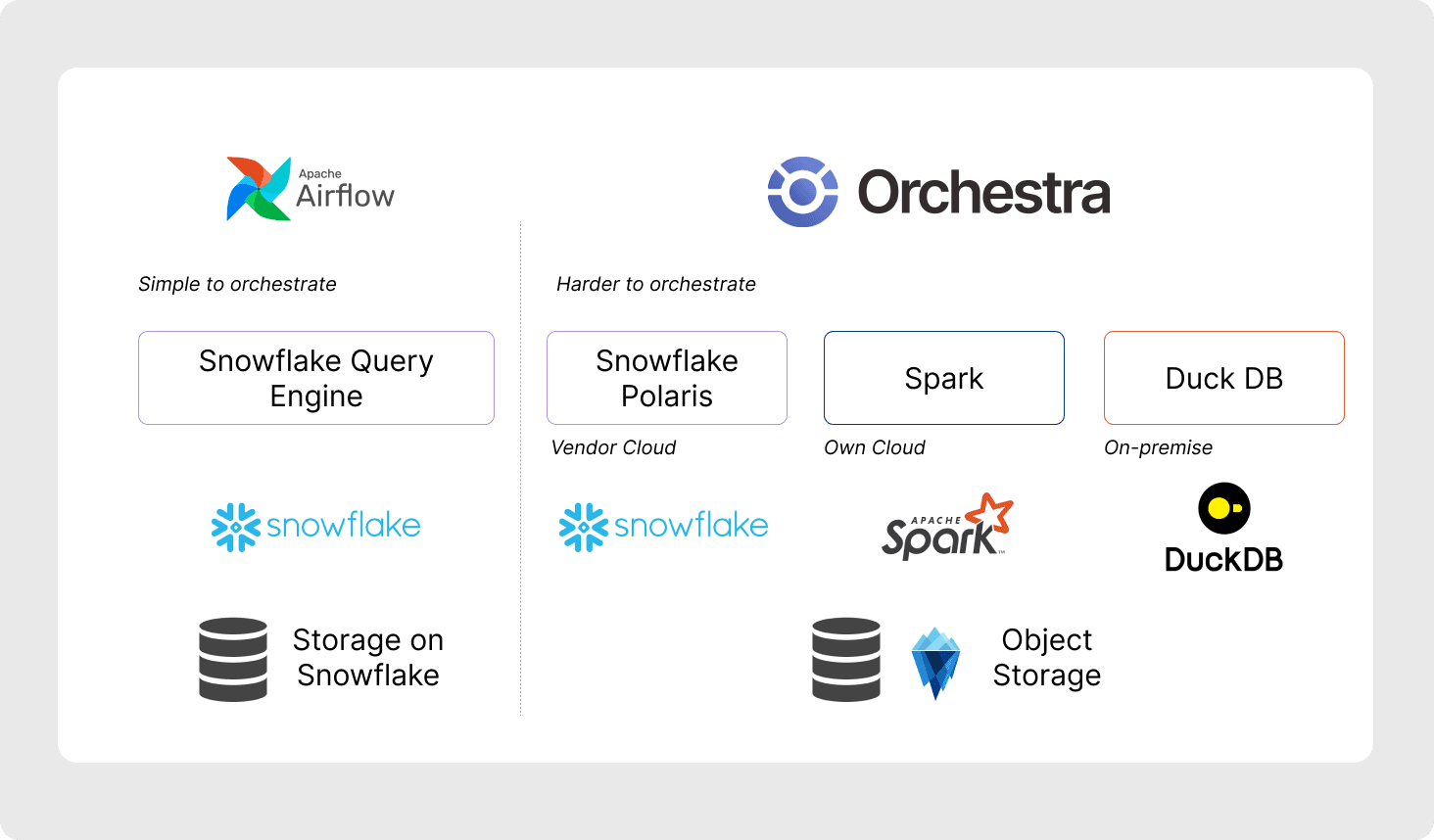
Orchestra handles multi-vendor storage and compute architectures.
How does Iceberg affect your business intelligence?
Changing where aggregated, gold-layer data sits impacts business intelligence and dashboarding. Popular solutions such as Power BI, Tableau and Sigma are directly connected to traditional data warehouse environments like Snowflake and BigQuery.
A complete migration to an open table format such as Iceberg means your dashboarding solution needs to be able to query gold-layer or aggregated data where it sits (i.e., in object storage, ADLS Gen-2, or S3). You should assess whether this native support exists in your BI tool.
An alternative pattern is to leverage a traditional data warehouse for gold or aggregated layer data only. This means migrating your data transformations to Iceberg and adding a step to replicate this data from Iceberg to a serving layer like a warehouse. This pattern would hold your BI layer steady but inherently adds complexity and runs counter to Iceberg’s security benefits of keeping data within your infrastructure.
Closing thoughts
Iceberg may be the hottest topic in data infrastructure, but any migration requires serious consideration. Iceberg can offer massive benefits, which is why some of the world’s largest enterprises have already made the effort to adopt it. Your critical next step is to evaluate all of the things you need from your data infrastructure today and whether Iceberg can support those needs while providing superior performance.
As you get started, you absolutely should test your key use cases and implement Iceberg and your query engines of choice incrementally for those. That will immediately allow you to see if you can get performance and cost benefits. Note that an incremental or partial implementation ultimately would still leave you with data stored outside of your owned object storage, however, so you won’t fully reap the security benefits of a unified data store in your environment unless you fully migrate.
To learn more about data orchestration across your infrastructure, contact the team at Orchestra. To learn more about activating your data, whether from a data warehouse or your own Iceberg infrastructure, contact the team at Hightouch.

















