
The growing adoption of Apache Iceberg will revolutionize how enterprises use data. By the end of this blog, we’ll share why Iceberg is so exciting as a new technology in the data industry but also how it could disrupt the software industry as we know it. Let’s dive in.
Iceberg and the lakehouse
Apache Iceberg is a powerful and flexible open-source table format that works with cloud object storage such as Amazon S3 and Google Cloud Storage. Iceberg doesn’t directly define how your data is stored (like in parquet or ORC format) but defines how data gets organized logically, like a blueprint for structuring and accessing data efficiently. Iceberg is exciting because it offers high-performance data warehousing features to object storage like S3 (read more about features here). Iceberg therefore opens up a future where companies can use their own object storage like a data warehouse.
This isn’t an abstract theory: since being developed internally at Netflix and later open-sourced in 2018, Iceberg has already been adopted by many large companies including Bloomberg, Apple, LinkedIn, and Airbnb. Conceptually, most customers using Databricks are also leveraging a similar architecture with their open-source Delta Lake format. We’re increasingly encountering open-source table formats like Iceberg and Delta Lake in conversations with our enterprise customers and prospects about their data strategy.
Why’s this a big deal? Cloud data warehouses like Snowflake rose to dominance by separating infrastructure for data storage and compute. This significantly reduced costs and improved operations: companies now can collect and store vast amounts of data cheaply, and then only pay more for compute when they need to query that data. Iceberg can evolve this paradigm to the next logical step: decouple storage and compute entirely. If you maintain your storage layer in Iceberg, you can swap in any query engine (Trino, Spark, Snowflake, etc.) for any unique workload. This architecture is frequently called the lakehouse, and essentially is a “composable data warehouse” made of separate storage and compute layers.
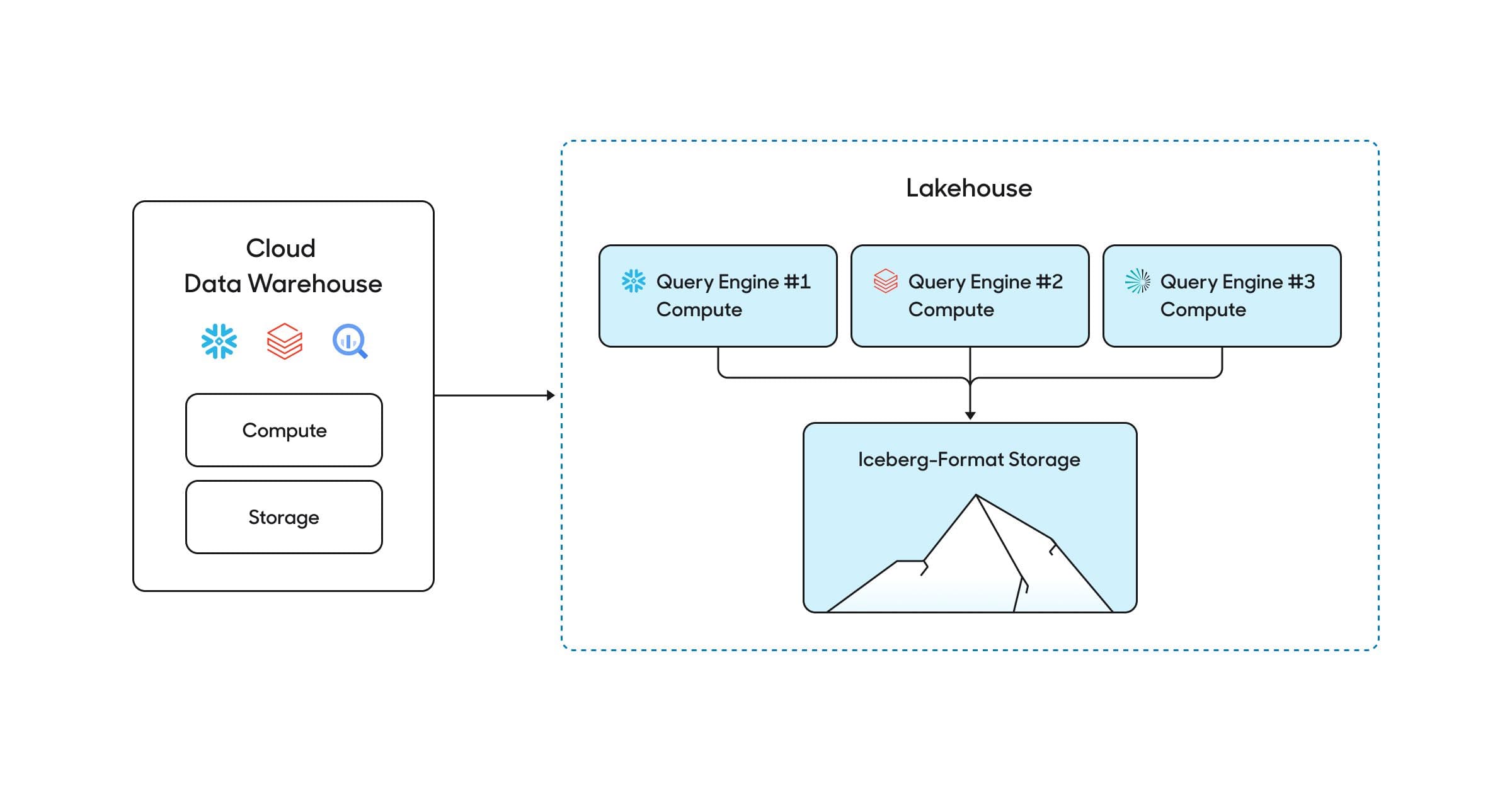
Companies can decouple compute and storage from a single warehouse. Credit to Tomasz Tungunz for inspiring this image.
The major cloud data warehouses are already adapting. Many have already acknowledged enterprises' demand for Iceberg table formats and now support them– both in and out of their managed storage environments.
- Snowflake has supported the ability to query from Iceberg tables since 2021, and supports the ability to manage Iceberg tables directly within Snowflake.
- Google’s BigLake is compatible with Iceberg table formats.
- Databricks has long promoted its open-source format Delta Lake, with similar advantages to Iceberg, and has also committed to supporting Iceberg storage format.
- New players like Tabular, founded by the original creators of Iceberg, have also entered the market, making it even easier to build and maintain an independent, universal storage platform built on Iceberg.
What are the benefits of the lakehouse?
Composable architectures are gaining popularity across the software industry. We personally have been pioneering the Composable Customer Data Platform (CDP), which decouples previously bundled CDP features and allows companies to choose best-in-breed tooling around their own data infrastructure. Similarly, the lakehouse allows companies to select best-in-breed query engines around their own storage.
Like any disruptive technology, the lakehouse can only gain traction by demonstrating enough value to enterprises that they adopt it. Here are some of the reasons driving companies to make a change:
- Own your data. With your own object storage in Iceberg format, you maintain complete ownership of your data within your own private cloud network. This immediately reduces security risk (as your data no longer lives in another SaaS tool’s infrastructure), and you avoid ever getting locked into some proprietary storage format (that’s incompatible with other query engines).
- Choose the best query engine for each task. By definition, each query engine performs tasks differently. Some are better than others at different projects– which is why you’ll often see enterprises using both Snowflake and Databricks, for different use cases. The demands for exploratory analytics, business intelligence (BI), data transformations, machine learning, and AI are all radically different. Rather than having to use a single query engine associated with the data warehouse to perform all of these tasks, a company can easily swap in different engines that are optimized for each task.
- Reduce costs. All of the benefits discussed above also have cost implications. Choosing the most efficient query engine for each task will allow companies to save on total compute costs and negotiate between competitive query engines for better prices. Companies can also save money if they choose to store data in their own environment rather than paying a premium for storage in a managed warehouse.
How the lakehouse will revolutionize SaaS
Ok, so some major enterprises have made the shift to Iceberg-based warehouses–and more are likely to follow suit if the benefits of this architecture become better known. What does this mean for technology in the years ahead?
Fundamentally, we believe that the future will involve bringing compute to data, rather than sending data to compute.
We think the most significant disruption will come with the rise of an open market for query engines–which will drive innovation, greater performance, and reduced cost across use cases. Existing data platforms that offer managed storage and compute, like Snowflake and Databricks, will compete alongside dedicated query engines like Trino and Spark for different projects at different companies. New query engines will emerge as well. Either way, companies won’t be locked into one query engine associated with their data warehouse– they’ll have choices.
Data-intensive SaaS apps could also develop their own query engines on top of Iceberg storage. For example, some analytics companies like Amplitude have built specialized databases to perform very fast time-series and event analytics queries for interactive analytics based on real-time data. While it’s not possible (to our knowledge) to achieve equivalent performance on standard cloud data warehouses like Snowflake or Databricks, with Iceberg, it’s theoretically possible to build a fully “warehouse-native” version of Amplitude. Instead of making a copy of customers’ data and storing it in a specialized database, Amplitude could develop a time-series query engine that sits directly on top of their clients’ Iceberg tables.
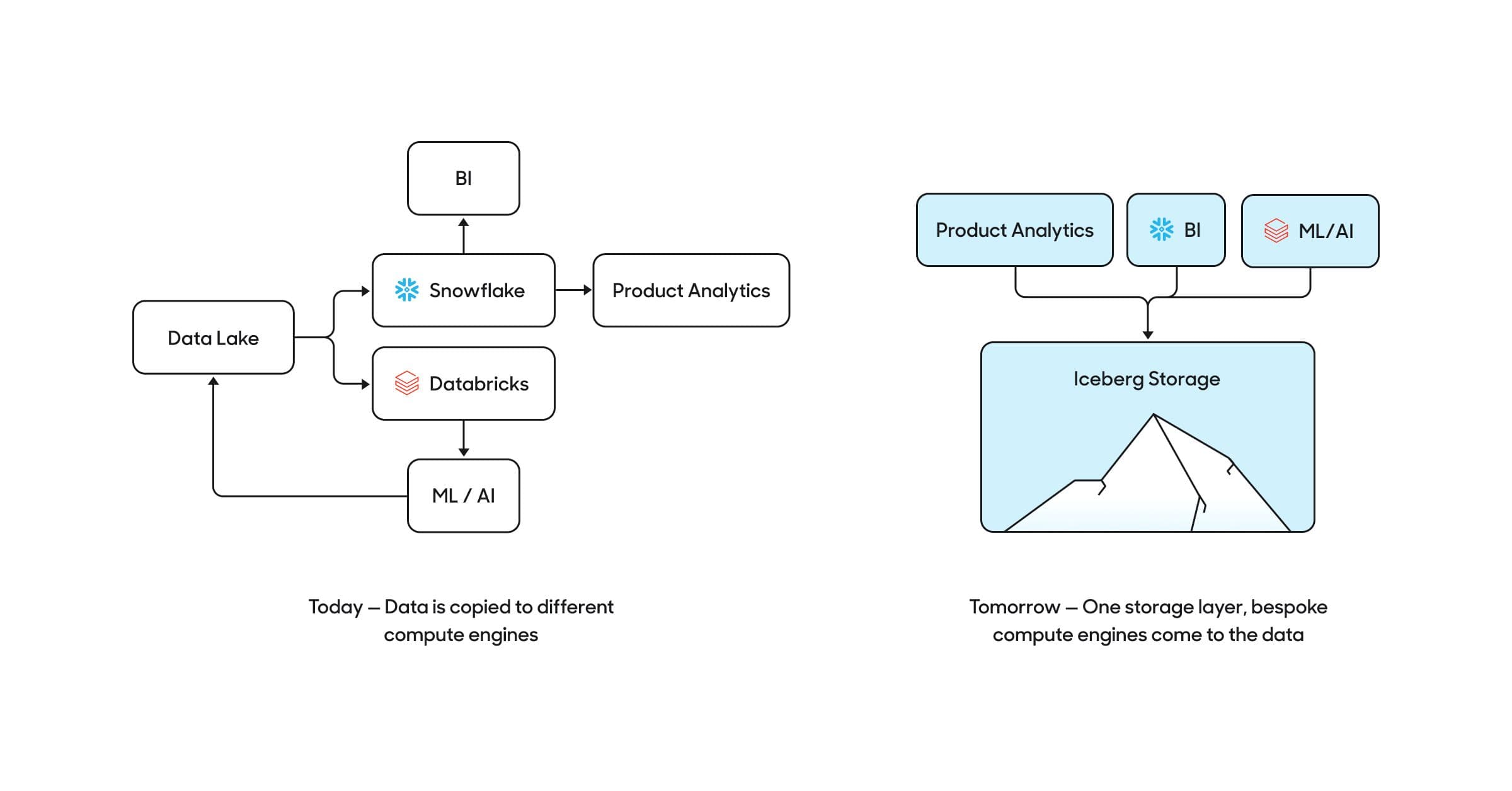
Today, enterprises copy data to different compute engines for different needs. In the future, companies will keep their data in one unified storage layer, and bring different compute engines to their data. Data-intensive SaaS apps may bring their own compute engines directly to this storage layer as well.
Another use case Iceberg adoption could influence is data sharing. If many large enterprises standardize to Iceberg format, there’s a world where these organizations could all easily share subsets of their data with each other without requiring any duplication, which could be cross-cloud and agnostic of their respective query engines. At this time, Iceberg does not provide the necessary primitives to implement an engine-agnostic data sharing governance protocol, but given all the momentum we're seeing around data clean rooms and data sharing, it's an exciting opportunity.
All told, the lakehouse is poised to change how individual enterprises operate, shift the entire business model for managed data warehouses, and create a new open market for query engines that will entice existing SaaS apps to change their operations. The holistic scope of these changes is staggering: practically every part of the modern data industry might look radically different in just a few years if this comes to fruition.
Closing thoughts
We’ve laid out a lot of bold predictions in this blog. Some of them may not come to pass–but some will. It’s definitely worth keeping an eye out for your own company to plan for this future.
Going through this exercise ourselves: what do these changes mean for Hightouch? We’ve built our entire company on the thesis that the cloud data warehouse will disrupt how businesses operate. We know this will continue to be true: companies work better with centralized source-of-truth data. What stands to change is the nature of the warehouse, whether managed by today’s top players or in different companies’s lakehouses. We will adapt to continue turning data into action wherever it’s stored.
If you’re interested in sharing your thoughts or learning more about Hightouch, get in touch!
Recommended reading:
The database is getting unbundled- Tomas Tunguz, Venture Capitalist at Theory Ventures
Iceberg in Modern Data Architecture and The Case for Independent Storage- Ryan Blue, Co-Creator of Iceberg and Co-Founder and Co-CEO of Tabular
“Bring Your Own Storage” (BYOS) Has Never Been Cooler - Hugo Lu, Founder and CEO, Orchestra
The Icehouse Manifesto: Building an Open Lakehouse- Justin Borgman, Chairman and CEO at Starburst
Benefits of Apache Iceberg on Snowflake - Avinash Sharma, Data Engineering Analyst at Accenture

















