
Since the inception of data, figuring out how to move data between systems has been a constant challenge. With an increasing amount of data generated every year, this problem has only become more prevalent. Ultimately there’s a lot to consider when it comes to moving data, which is why data integration is so important.
What is Data Integration?
Data integration is the process of collecting and consolidating data from your many different data sources and combining it into a single location to produce analytics. The goal of data integration is to make your data more valuable by merging and contextualizing it so your business teams can take action.
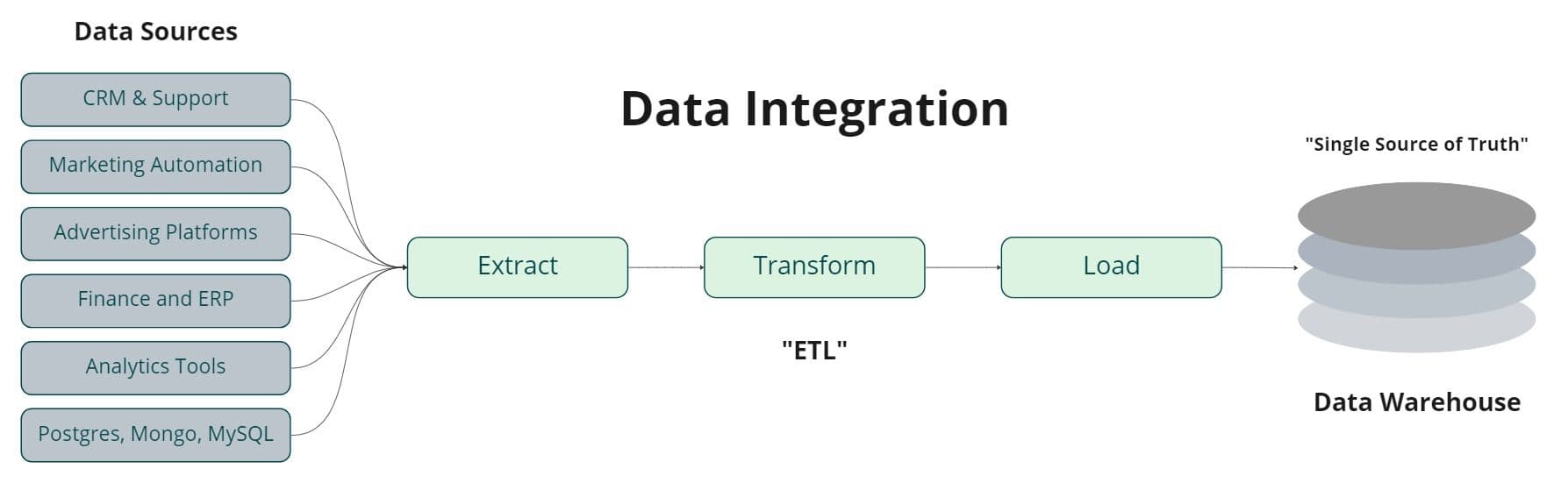
Most companies have hundreds, if not thousands, of external sources, and data is often scattered across numerous disparate systems like Hubspot, Salesforce, Netsuite, etc. In fact, at some point or another, you’ve probably found yourself hopping back and forth between tools to access the necessary data. Data integration eliminates this problem by consolidating your data into a single platform. It’s the underpinning process that powers the entire data ecosystem.
How Does Data Integration Work?
While data integration is the process of moving data from a data source to a target destination. The ongoing process involved in transferring data from point A to point B is relatively complex. At its core, data integration is a data engineering problem only addressed through a method broadly defined as ETL (extract, transform, load). ETL is the data integration process engineers created to define how data moves from one system to another.
- Extract: This step involves collecting and extracting data from source systems, whether it’s your business applications, internal databases, web services, or even flat files.
- Transform: In the transformation step, the data from your sources is cleaned and processed to align with the schema structure of your target system. This includes converting, restructuring, standardizing data types, or even replicating, renaming, and deleting specific fields.
- Load: The final step of ETL involves loading your transformed data to the target destination. In most scenarios, this is a data platform (e.g., a data warehouse or a data lake.)
Under the hood, ETL is essentially the process of reading data from an API (application programming interface) and writing that same data to another API (e.g., usually a data warehouse or an operational system.)
Why is Data Integration Challenging?
No two data sources are alike, so consolidating data and understanding how that information contextualizes together is complicated. Every system has its own unique schema structure to define how your data is organized and structured to govern the fields, tables, and relationships of your data.
Additionally, every data source and destination has its own unique API with parameters in place outlining how you can read and write data from one system to another. It’s really difficult to understand how your data relates to other sources.
You have to ensure your data is modeled and transformed to align with the schema structure of your target destination; otherwise, it’s impossible to ingest your data into your target system. Inevitably, you need to build pre-defined models that align with your downstream systems.
This is more straightforward if you’re ingesting your data into a data warehouse or data lake. However, the process becomes much more complicated for SaaS applications and operational systems because you have little to no control over how they’re configured.
Data integration also has another added level of complexity because before you can even start integrating your data into one system, you first have to identify your end goal and requirements, which means:
- Identifying your sources: How many sources do you have? How much data are you trying to ingest into your destination?
- Identifying your destination(s): Where are you trying to ingest the data? What teams need access to the data? How should this data be modeled before it arrives at your destination?
- Identifying your needs: What is the latency requirement for your data? Do you need real-time integration via streaming or will you be ingesting via batches on a predefined schedule?
- Building your pipeline(s): Will you purchase an off-the-shelf tool to move your data or build a custom pipeline in-house?
Data Integration use Cases
Data centralization is the core use case behind data integration. Companies usually have slightly different reasons for centralizing their data, but three use cases fall underneath centralization: analytics, activation, and security.
Analytics
The immediate and most prevalent value add to data integration is analytics. Centralizing your data into an analytics platform means your data teams can run queries, build data models, and identify KPIs (key performance indicators) to power high-level business decisions. Without data integration, it’s impossible to answer complex questions like:
- What is our churn rate?
- What is the lifetime value of company X?
- What percent of new signups translate into tangible sales pipeline?
- How many new workspaces were generated from our pricing page?
Data Activation
Data Activation comes after analytics, but it’s equally important because insights are useless unless you act on them. Having your data in one centralized location means you can use it to drive outcomes. Here are some practical examples:
- Your sales team wants to know which accounts are at risk of churning.
- Your marketing team wants a list of customers they can retarget on Facebook.
- Your customer service team wants to know which tickets they should prioritize.
Data Activation focuses on moving the enriched, transformed data out of your warehouse and syncing it back into your operational tools so your business teams can build hyper-personalized customer experiences. Data Activation also gives you the ability to monetize and sell your data.
Security
Data integration also has huge security implications. Accessing your data in one location makes it easier for you to manage governance and control user access across your company. The ability to automatically provision and de-provision user access to specific tools in your technology stack is a huge advantage.
Types of Data Integration
ETL
With ETL, you extract your data and transform it in a staging environment before loading it into your end destination. The entire premise behind ETL is to ensure your data is in a quality state before loading it into your destination.
ELT
With the rise of cloud data platforms and analytics tools like Snowflake, BigQuery, and Databricks, companies have shifted away from conventional ETL to what’s now known as ELT (extract, load, transform.) ELT takes place in the cloud, and since the transformation step no longer happens before the data your loaded, it’s drastically faster and more efficient. As an added benefit, you no longer have to guess how your data should be modeled/transformed for your downstream use cases.
Reverse ETL
Reverse ETL is basically the same as ELT, but rather than reading from a source and writing to a destination, with Reverse ETL, you’re reading from your warehouse and writing that data back to your data sources (e.g., your SaaS applications, internal databases, operational tools, etc.)
First-Party Integrations
Some data sources have built-in integrations to send data between systems, and these are commonly referred to as first-party integrations. For example, Hubspot has a native integration with Salesforce that allows you to move data between the two applications seamlessly. It’s important to note that most ETL, ELT, and Reverse ETL tools provide out-of-the-box integrations to seamlessly move data between systems.
Custom Scripts
Many data teams build their own integration systems by writing custom code and integration logic in various languages like Python, Scala, or even Javascript. The problem is to run these custom applications and scripts, you need a way to orchestrate your workflows. Usually, this means building an orchestration layer or purchasing an orchestration tool to run in parallel to your pipelines and manage your integration flows.
iPaaS
iPaaS (integration platform as a service) are fully managed platforms designed to move data between various systems. These tools are built around low-code UIs with drag-and-drop interfaces that enable you to visually build workflows and move data. The workflows are designed around triggers that you define. Triggers are specific actions and events that take place in a platform (e.g., email opened, page viewed, contact created, payment processed, etc.)
Once an event is triggered, iPaaS tools kick off predefined actions built on various dependencies (e.g., if this, then that.) Workflows can work great for simple use cases (e.g., when a lead requests a demo in Marketo, create a new lead in Salesforce.) For anything more complex, they can quickly become difficult to scale and maintain. Every workflow or new integration with another tool introduces another pipeline, which quickly creates a complicated spiderweb.
CDPs
CDPs are fully managed marketing platforms that automatically integrate with various upstream source systems so you can easily consolidate all of your data into one platform. The added benefit to the CDPs is that they provide several activation features so you can easily build and manage user cohorts and then sync that data directly to your frontline business tools.
The downside of CDPs is that most companies would rather centralize their data in a data warehouse because CDPs are really only designed to handle user/account-level objects. This cookie-cutter data modeling approach inevitably ends up causing trouble, and this is why most companies prefer to consolidate their data into a data platform like Snowflake or BigQuery. On top of this, CDPs force you to pay for another storage layer in addition to your data warehouse.
Benefits of Data Integration
Without data integration, it’s impossible to contextualize your data or fully utilize it. Data integration enables you to define metrics and KPIs in a single source of truth. Having all your data in your warehouse unlocks use cases that weren’t possible before (e.g., analytics, activation, security, etc.) Data integration can also provide substantial cost savings because you can control exactly where your data lives and ensure that everyone across your organization is looking at the same information.
Data integration makes sure your data is where it needs to be. This creates huge time savings because your business users no longer have to hop across multiple tools (e.g., Salesforce, Netsuite, Hubspot, etc.) to gather a complete picture of your customer. Choosing where your data is ingested also has significant cost savings benefits for analytics because you can move your data to a cheaper and more efficient system for processing specific workloads (e.g., transforming your data in a data lake using spark.)
Data Integration Tools and Services
The data integration space is enormous, and many different integration solutions are available. Here’s a list of the most popular integration technologies and services in their respective category.
Informatica (ETL)
When it comes to legacy ETL, Informatica is one of the most widely adopted technologies in the space. Informatica has been around since 1993, and it was created to handle legacy on-premise systems and minimize storage costs in the data warehouse. Today the company also provides cloud data integration and connects with a wide variety of data sources and destinations, but it’s considered an older player in the data integration world.
Fivetran and dbt (ELT)
Fivetran is a cloud-based, modern data integration platform that offers hundreds of pre-built connectors to various data sources to help you ingest data into data platforms like Snowflake, BigQuery, Databricks, etc. Fivetran focuses entirely on extracting and loading data, so most companies end up pairing it with dbt to tackle the transformation aspect.
dbt is a transformation tool that helps you build, manage, and run all your SQL transformation jobs in your warehouse. dbt introduces software engineering practices to your data pipelines so you can manage dependencies between your transformations, track the lineage, and build reusable models in a scalable way.
Hightouch (Reverse ETL)
Hightouch is a data and AI platform for marketers that lets you leverage all of the existing data in your warehouse and sync it directly to your frontline business tools, so teams can take action in the tools they already use. Hightouch runs on top of your data warehouse, so it never stores any data. You can access your existing models and build custom audiences to sync directly to your downstream tools.
Segment (CDP)
Segment is a customer data platform that helps you collect user events, build audiences, and sync that data to thousands of downstream destinations. Segment supports a minimal number of sources, so if you want to sync data to your downstream applications, you’ll first need a way to ingest your customer data into the platform.
Workato (iPaaS)
Workato is a workflow automation platform that offers over 1000 different integrations with various SaaS applications, databases, and APIs. Workato lets you build point-to-point connections between multiple systems like Marketo and Salesforce via workflows that you define.
Airflow and Dagster (Orchestration)
If you’re looking to build and maintain your own in-house data pipelines, Airflow and Dagster are great orchestration options for creating, scheduling, monitoring, and managing your integration jobs and workflows. While these platforms don’t have any integration capabilities, both tools offer a web-based UI where you monitor and manage your pipelines, and they’re entirely open-source and customizable.
Final Thoughts
Without data integration, your data is siloed across multiple disparate sources. Data integration allows you to contextualize your warehouse data so you can drive critical business decisions for analytics and activation. Data integration projects are complicated, and they’re not getting any simpler as the number of technology tools in a given company only continues to grow.
Ultimately, your primary goal with data integration should always be to centralize your data into a warehouse. Doing so will set you up for success and unlock all of the additional use cases you need to address.

















